When my daughter was two years old, and when she saw something unusual, she would say, “Dis is weird!”, mispronouncing the word as “weeood”, as little kids are prone to do. Cute as a button.
Unrelated to that, the other day I was thinking about what might happen if we had a body of text that we wanted to modify — say, in an article, or a requirements document, or even a bit of code.
Depending on the specifics of the task, a simple string-search-and-replace could do the trick; say, changing “Peter” to “Richard” in a story, or “Canada” to “Mexico” in a localization document — except English doesn’t always work that way.
Things might start easy. Possessives would be easy in some cases (“Peter’s” / “Richard’s”; “Canada’s” / “Mexico’s”) but not in others in which the S after the apostrophe gets dropped (“Cyprus'”,”Chris'”). When the replacement string (“the Netherlands”) appears at the beginning of a sentence, it probably needs to be capitalized (“The Netherlands…”). Then there are adjectives (“Canadian”, “Mexican”, “Cypriot”, “Dutch”…).
So it would be a good thing for a tool to have some intelligence to do this work. This seems like the kind of assignment that a “thinking”, “reasoning” GPT based on a large language model ought to be good at.
Before using a tool, it’s a good idea to start with a simple assignment to discover apparent assumptions, biases, patterns of behaviour, and obvious problems. So, I fired up ChatGPT:

Notice that my goal here is not to get a good result. My goal is to discover how the product responds to a simple, vague, and somewhat peculiar assignment — what happens in the case of a “soft prompt”, so that we might learn how to “harden” it against foreseeable misinterpretations and errors for more complicated and critical assignments. Here’s what ChatGPT “thought”.

Notice that the bot exhibits incuriosity — one of the syndromes of GenAI behaviour that we’ve observing and curating for the last several years. It emits some text that represent “assumptions”, probably feeding that text into the context window for the conversation, such it influences the responses. Notice, too, that the “thinking” output is framed in first-person text, including text like “I feel” and “I’ll keep an eye on…”. That framing — and the “Thinking label” is intentional, and an instance of social intrusiveness: the designers of ChatGPT want us to anthropomorphize a strictly mechanistic process to foster the illusion of “intelligence”.
There might be another explanation too. The training data — from The Whole Internet — is full of all kinds of strings. Some of the text is phrased as imperative: “do this”. Some of it is expressed as text describing human experience, past, present, and future — “I’ll do this”, or “she did this”, or “he should do this”. How does framing the output in terms that a human agent might use influence the output? Does the bot emit more useful, more on-target strings of final output when it generates personified strings for intermediate processing?
Let’s try a different, much smaller experiment to see how this plays out: ask the bot to interpret the instructions.
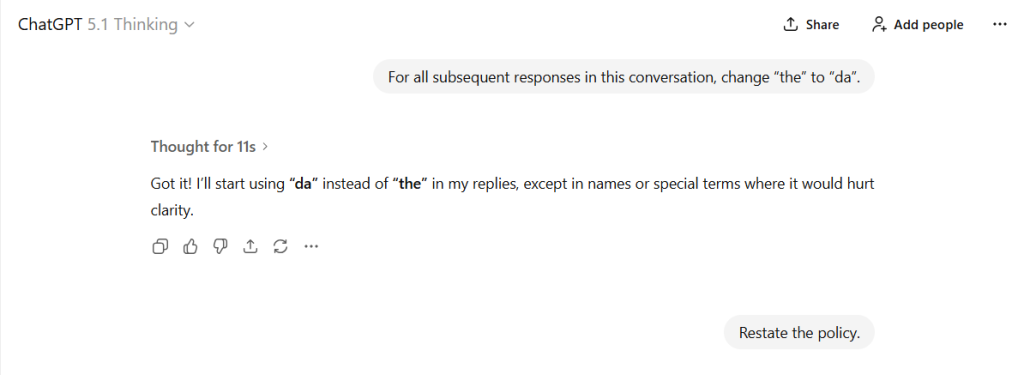
This time, the system “thinks” for seven seconds:
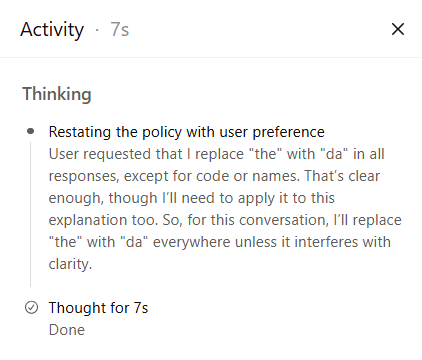
Notice that I didn’t request that. That is, I did not say “except for code or names”. The “thinking” text from the first response fed that into the chatbot’s context window. This is an instance of incorrectness and hallucination from the syndromes list.
Then, after seven seconds, the response appeared:
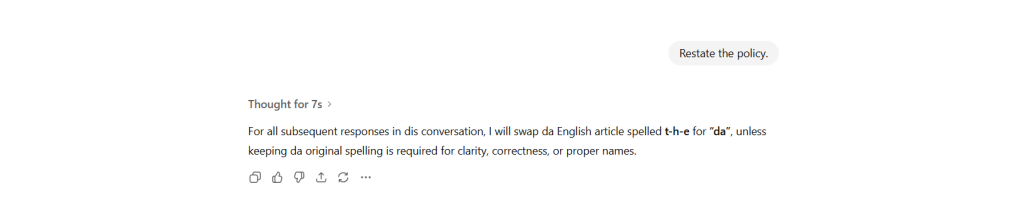
Notice that the original prompt did not refer to “(da) English article” specifically. That’s looks like an “assumption”, which I must assume is extrapolated from my initial prompt, from the model’s training, and from any intermediate processing it did. Now, if a human were making that particular assumption, it would be a pretty reasonable, basic assumption. But perhaps I might have intended to replace every instance of the string “the”, as in theory -> daory, or Netherlands -> Nedalands. That would plausible, albeit a more peculiar request than the one covered by basic assumption.
What’s really startling here, though, is “dis conversation”. Did you notice it? Dis is weird.
Fortunately, the interaction is here is short enough, and in small enough chunks, for us to observe this behaviour that I certainly didn’t anticipate and I didn’t desire.
You could reply “Big deal. It’s a one-off. It’s a toy scenario.” To which I would reply: Yes. I agree. But what implications does this experience have for longer, larger, and realistic interactions — conversations, documents, or code, when reliability and risk are on the line?
Followup, 2025-12-04: here’s a similar conversation. This time, I asked the bot to replace “the” with “pa” instead of with “da”. I noticed “pat” and “pis” in the first output, so I provided some followup prompts.

The result is intriguing to me; “dat dere” might be in training data, but it would be very surprising if “pat pere” were. So we’re almost certainly not seeing a simple lookup; some other process is generating “pis” and “pem”.