Last time, we looked at what the business wants from development. What does the business want from that part of development we call testing?
Sometimes people say that what the business wants from testing is confidence — reassurance that everything is okay. This is understandable — confidence is a good feeling for designers, developers, managers, and the rest of the business. Confidence and reassurance are not the business’s goal, though; a valuable, trouble-free product is.
As a former program manager, I can tell you what I wanted from testing. I wanted an answer to these two questions:
What is the actual status of our product?
Are there problems that threaten the value of the product, or the on-time successful completion of our work?
A responsible development organization needs to understand whether the product that it’s got is the product that it wants — or doesn’t want. If there’s a problem that threatens the on-time completion of work, a manager responsible for that work needs to be aware of that problem so that it can be addressed and managed. The journey towards that awareness begins by recognizing the risk that we can be fooled, and that problems can elude us.
Where might problems exist? Problems can exist in any product. As I mentioned at the beginning of this series, for our purposes here a product is anything that anyone has produced. That includes a feature in an application; a specification that describes it; a prototype; a user story; a one-line change; a set of ideas about who our users are; a build, or a release; a project plan; a workflow. Our work is a product, too — from the entire project down to anything that we might be working on within it, at any level of granularity.
What kinds of problems might exist? It’s relatively easy for software developers to think of problems in terms of coding errors that lead to incorrect output from functions. Such problems are important, because if a function doesn’t produce correct output, it’s very likely that some requirement will not get met. Coding errors of this nature can be relatively easy to find, too, via output checks that are created as part of the development process, and that can be re-run after every change. Those output checks produce a nice, clear, binary result — yes/no, pass/fail; green/red. What’s more, they can provide very fast feedback to developers, so that coding errors can be addressed quickly without getting buried. Sound development management will insist on the kind of testing that reveals problems in the product’s functions.
However, there’s an asymmetry: functional incorrectness will likely result in some requirement not being met. However, functional correctness does not guarantee that any particular requirement has been met. Reliable checks will alert us to coding errors that we have considered. They will fail to alert us to two kinds of problems: coding errors that we have not anticipated; and problems that are not apparent from the perspective that we’re taking.
Consider: some people who advocate strongly for unit testing insist that if the test requires the unit to interact with the database, it’s not a unit test; therefore, the unit test should interact with a mock of the database, instead of the real thing. I might be inclined to agree. However, it should be clear that unless the mock perfectly represents the real database, all of its contents, its performance profile, and every possible interaction with it, there’s a risk that the unit test won’t catch a problem with the real database. And that’s okay for the purposes of unit testing directed towards coding errors not related to interaction with the database.
Similarly, automated checks at the API level are very good for detecting problems introduced by changes in functions called by the APIs. Such checks can be extremely useful, but because they’re created by people inside the development group, they’re often influenced by the Curse of Knowledge. They’ve been created by people inside the development group. They tend not to represent an outside programmer’s naturalistic, real-world encounters with the API. They don’t tell us much about the confusion and frustration that the programmer will experience with poor documentation, oversimplified examples, and confusing error codes. And that’s okay for the purposes of API-level testing directed towards coding errors in those underlying functions.
Maybe we’ve planned carefully, and examined each component or module or function as we’ve built it, and we’re satisifed with each one. That’s good, but the product is not just an assemblage of parts; the product is a system in its own right, and also an element in a complex, socio-technological system that includes people, data, and other technologies. The system is comprised of all of its components and the relationships between them — all of which change over time.
Some problems are not intrinsic to a given component. Some problems result from unhappy interactions between components that are otherwise fine on their own. The product works splendidly on one platform, but suffers incompatibilties with another. Users produce data that is more varied and challenging than we anticipated. Things start off fine, but as data accumulates over time, performance might suffer. In other words: our vision for the product, our awareness of what matters to people, and problems about the product are to some degree emergent.
A built product must satisfy a range of requirements, based on multiple dimensions of quality for a wide community of users and other stakeholders. In the Rapid Software Testing namespace, we consider capability, reliability, usability, charisma, security, scalability, compatibility, performance, installability as things that have direct significance for users. Such problems result in loss of customers’ time, money, or data, and follow-on delays or losses for their customers. Those problems can lead in turn to disappointed or angry customers, bad publicity, or societal outrage.
There are also quality criteria that are indirectly significant to users, and more directly significant to the business. Things might be fine for programmers inside the current development group, right now, but other programmers may experience problems later — problems related to maintainability, portability, and localizability. Problems weren’t noticed by the programmers might result in trouble for other people inside the organization — the support people, the database administrators, the testers.
When some dimension of quality is significantly diminished or absent for some person who matters, that person will claim — accurately — that the product doesn’t work to their satisfaction. The consequences of all this: higher costs, lower value, loss of reputation, and less profit for the business. Sound development and business management will require the kinds of testing that reveal not only coding errors, but problems related to any and all of the explicit and implicit requirements, all of the relevant quality criteria, and to the risk that they won’t be satisfied for some person or group that matters.
The business may want confidence, but responsible people don’t want that confidence to be based on theory or illusions. Warranted confidence comes from thorough, capable investigation and evaluation of product and business risk — that is, from responsible testing; and dealing with revealed risks until there are no more significant ones to address.
Let’s review the four kinds of business risks I identified in a previous post.
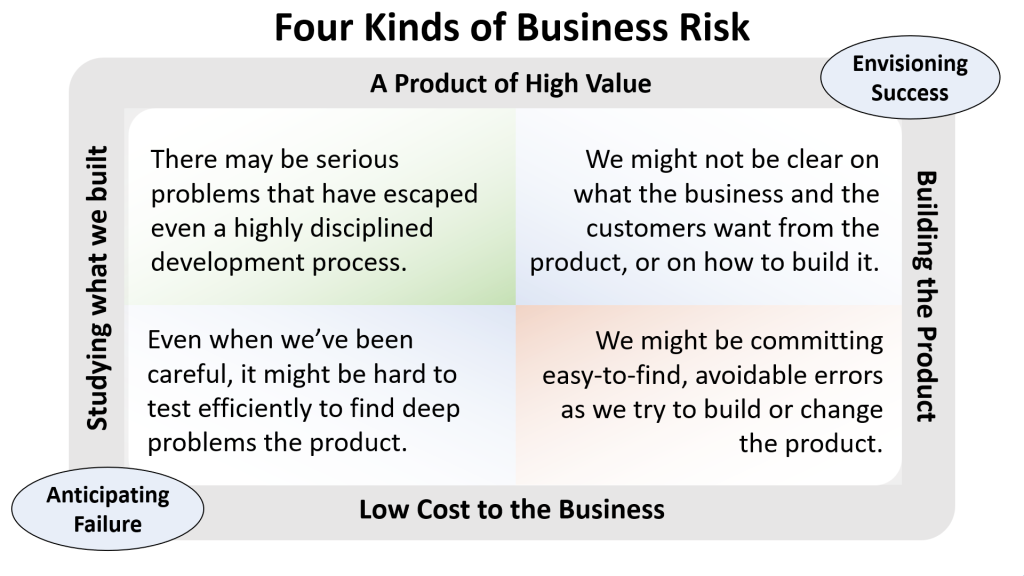
Each of these risks prompts four kinds of questions, and four frames for testing work.
- As we optimistically envision success, there’s the risk that we might not be clear on what customers or the business want from the product, and we might not be clear on what we need to do to build it. Are we sure we know what everyone wants from the product? This suggests review and testing work focused on our intentions.
- As we try to build the product diligently, there’s risk of committing relatively easy-to-recognize, avoidable errors. Are we building what we think we’re building? This suggests review and testing work focused on maintaining programming discipline.
- When we anticipate failure, we realize that knowing what to build and avoiding errors might be harder than we think, so we might need to test more deeply. Given that, there’s a risk that looking for subtle and elusive problems might be harder and slower than we or the business would want. Are we ready to test efficiently? This prompts us to consider testability.
- Until the product has been built, what we know about how it actually works is based on theory. Even when we’ve designed and built the product diligently, there’s the risk that important problems might have slipped by us. The product may have bugs that thwart the needs and desires of the people affected by it, or the product may introduce new problems. Have we tested enough to know about every important and elusive bug? When there’s risk, we must test deeply and responsibly. We can frame this kind of testing in terms of realization: testing the realized product, and realizing problems that might have emerged.
In the next post in this series, let’s look at each of these framings — intention, discipline, testability, and realization — in depth.
Thanks for sharing this! The concept of four frames for testing is an interesting approach, and it’s great to gain more insight into how testing can be structured effectively.