Are you interested in learning about something on the Web? How about learning about my approach and my services, Rapid Software Testing? You could use a search engine to look it up. But there’s a problem; it’s ominous; and it goes way beyond Rapid Software Testing. It has consequences for the entire world of online search.
The problem came home to me on April 6, 2024. I had created a post on LinkedIn, and had included an image of the Rapid Software Testing Framework, a diagram developed by James Bach and me. Many people reposted my LinkedIn post (thank you to all who did). For economy, LinkedIn provided a low-resolution version of the image. One correspondent asked if a high-resolution version was available.
My immediate (and definitely uncharitable) reaction was that this was a lazy request. The devil on my shoulder wanted me to provide a snarky reply: “why not try typing ‘rapid software testing framework’ into a search engine, and get it yourself?”. Even worse, the devil suggested that I paste “rapid software testing framework” into lmgtfy.com (it stands for “Let Me Google That For You”). Bad devil! Doing that would be neither polite nor helpful, and after a moment the angel on my other shoulder prevailed.
I was on my iPad at the time. I was pretty sure I had created a keyboard shortcut that provided a link to the RST Framework diagram. Turns out I hadn’t; to help the fellow on LinkedIn, I get the link myself. I typed ‘rapid software testing framework’ into DuckDuckGo. Here’s what I got.
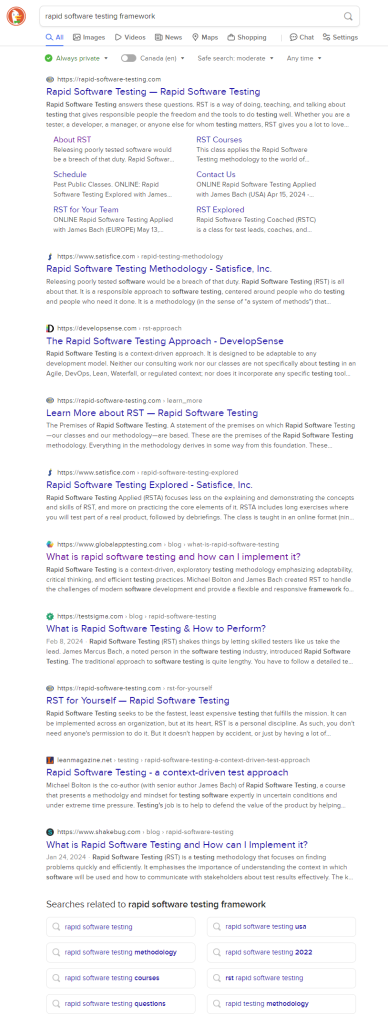
Look over the links. The first few point to material from James Bach (satisfice.com), and from me (developsense.com), and from a site that we develop co-operatively (rapid-software-testing.com). There’s also a link to an interview with me. No problem there.
Mixed in with all that are links to pages that we didn’t produce, but that purport to talk about Rapid Software Testing. Bits of that material are marginally helpful and to some degree accurate. Some material provides attribution (but annoyingly, no references or links to the original sources; our stuff). Some of of the material is plagiarised. Some of it is spectacularly wrong and misleading.
The wrong stuff and misleading stuff gets pushed up in search results, above authentic, helpful and accurate material, because of various search engine optimization hacks. (I’m presenting the search results here as an image in the perhaps-vain hope that the bogus results will get less attention from search engines.)
This sort of thing not new. Plagiarism and SEO hacking have been happening and increasing for years. What’s new is that more and more of the wrong and misleading information about RST is obviously generated by Large Language Models (LLMs).
Getting authentic information about RST is getting more difficult, and SEO manipulation has been making it more difficult. That’s a problem for me, and maybe it’s a problem for you too. That’s not so great, but it’s only a symptom of something far more dark and dangerous. Getting facts about anything is getting more difficult, too, and that’s a problem for anyone using the Web. And the problem is about to explode in all of our faces, and it’s not at all clear — certainly not yet — how anyone can do anything about it.
Here’s the problem: LLMs are poised to destroy Web search as we know it.
Here’s how. The largest LLMs these days have been trained by vacuuming up data from the web and other sources of information on the internet. Using the text from the prompt and that huge body of training data, LLMs produce strings of text that are statistically plausible. As Rodney Brooks cogently says, they’re not designed, intrinsically, to produce output that is right; they’re designed to produce output that looks good.
That’s a problem for several reasons. Much of the information on the internet is already of dubious quality. Some information used to be accurate (“the Queen of the Great Britain is Queen Elizabeth II”), but is no longer accurate because things change (R.I.P.) and pages go out of date. Some stuff on the web was incorrect or inaccurate all along (“the 2020 election in the U.S. was stolen!”). Some subjects are controversial (despite evidence and facts proven in numerous court cases, some people still insist that the 2020 election was stolen). Some things on the net are matters of opinion, rather than matters of fact. Lots of stuff is simply trivial, boring, or silly. Some of the material on the internet is bullshit — text or speech created with disregard for the truth.
Brandolini’s Law says that it takes an order of magnitude more effort to dispel bullshit than to produce it. LLMs, built to produce strings of text that resemble human writing at superhuman speed, make the bullshit problem much worse.
As of this writing, many people are aware that LLMs have a tendency to hallucinate — to spit out text that has no basis in reality. The output looks good, without any guarantee that it’s correct, factual, or truthful. That’s not an accident; it’s fundamental to the design of LLMs. So: LLMs produce bullshit at a virtually unlimited rate. We don’t have unlimited resources to dispel it.
Then the problem becomes explosive. When a new LLM is trained on data that contains bullshit produced by prior LLMs, querying the new LLM produces more bullshit. That output gets fed back into the round of training data, until the bullshit swamps the worthy stuff, rendering the LLM less and less useful. There’s a term of art for this in the research community: model collapse. This paper that describes the phenomenon mostly in terms of mathematics and formal systems; abstractions. At the end of the paper, things get much more direct and explicit:
The need to distinguish data generated by LLMs from other data raises questions around the provenance of content that is crawled from the Internet: it is unclear how content generated by LLMs can be tracked at scale. One option is community-wide coordination to ensure that different parties involved in LLM creation and deployment share the information needed to resolve questions of provenance. Otherwise, it may become increasingly difficult to train newer versions of LLMs without access to data that was crawled from the Internet prior to the mass adoption of the technology, or direct access to data generated by humans at scale.
“The Curse of Recursion: Training on Generated Data Makes Models Forget”, Ilia Shumailov, Zakhar Shumaylov, Yiren Zhao, Yarin Gal, Nicolas Papernot, Ross Anderson
(Here’s a more consumer-friendly report about that paper.)
The consequences are not just about LLM model collapse, though. The consequences lead directly to search engine collapse.
Inevitably, some LLM output is going to go back up on the web; probably lots of it. This means that the web crawlers will find LLM-generated content and index it. After that, search engines will return the garbage LLM output mixed in with the non-LLM material that was already on the internet. Without curation, that LLM output gets included in the next round of LLM training data, and pollutes the model. Output from the newly-trained model is of even more dubious quality than the last. That material goes up on the web and gets indexed by the search engines. The cycle continues in a feedback loop towards lower and lower quality of information on the net, and available from the search engines.
To put it simply: there’s a serious risk that LLM-generated content will undermine our ability to get reliable results from search engines. Search, as we know it, is in big trouble.
What if we want reliable, truthful information from an LLM? One proposed workaround is Reinforcement Learning from Human Feedback (RLHF), in which one of more humans vote on whether the output is valid or not. That depends on the evaluators being sufficiently expert to tell the difference, and sufficiently motivated to vote. However, when the question is “was this a good answer?” and the reply is a binary Yes or No, the questions of whether the human is an expert, and what’s wrong with the answer, are begged.
Another proposed workaround is Retrieval Augmented Generation; a kind of add-on to LLM-based systems in which the system incorporates some form of Web search as part of the process of generating and evaluating the output. That might work if the RAG algorithms were capable of knowing the difference between bullshit and non-bullshit content on the Web. But they’re not. If the search queries in question were supplied by human experts, the input might be somewhat better, but the responses would still be vulnerable to the hallucination, incorrectness, or laziness problems inherent in LLMs.
A lot of this was anticipated by AI researchers who are not AI fanboys. Notably, Gary Marcus wrote a post on this phenomenon over a year ago. I’ve been aware of the problem since then, but for me, last week, it got personal.
There may be glimmer of hope for humanists: real, human curatorship, backed by personal reputation and community-wide co-ordination will make a comeback. That would require something more like the classic and refined (but labour-intenstive) Yahoo model for search. How that will be aided by software and machinery remains an open question, for now.
Google’s expansive, open, and automatic (but less discerning) model for search has been useful and powerful for 20 years or so. But now the makers of Google and Bing are breeding the foxes that will ravage their own henhouses. I don’t see this ending well; certainly not in the short term.
Agree.
SEO tricks, manipulative content copying, auto-generated translation copy-pages, etc. have been messing up search results for a while now. ‘Personalized’ and ‘regionized’ (if that’s a word) curation of search results haven’t helped, also, various API based search features (like ecosia, while great idea provides slightly less accurate results) as well.
But LLM based content makes it much worse.
Side note:
25 years ago, when I explained how to search things on the internet to my dad, he was surprised: “wouldn’t this ‘specific way’ of searching make things more difficult, when we all have to do it “in the same way” – otherwise we don’t get the results? or we will get the ‘same’ results, – making us all very average?”
While back then I didn’t see his point, now it seems to be more clear – more and more content seems to be rehash of the same thing, not deep, not creative, not personal, but average. I’m worried that LLMs create exactly that – flavourless, general, average, possibly wrong or misleading, material.
The societal implications of this change are pretty wide ranging. What does a rational response look like? We already have enough issues with Human generated bullshit, and have proven ourselves incapable of building any kind of effective societal consensus around how to deal with this.
Humans have a knack for sorting things out over time, often in a pattern of two steps-forward, three back, four forward, half a step back, one step forward…
Over time, societies decide how to deal with stuff. There’s a (heuristic) principle from McLuhan’s (heuristic) Laws of Media: things (like bullshit) that become ubquitous without influence tend to go into reversal, and foster the opposite of their original effects.
I’m optimistic about humanity in the long term; but I am pessimistic in the short term.