A few nights ago, a colleague noted that he was impressed by ChatGPT’s capacity to evaluate a sentence. He had offered a prompt something like “Is honesty the best virtue” without the question mark, and was surprised that ChatGPT could infer that he had intended a question.
(In this post, I will use cLLMs to refer to chatbots based on LLMs.)
I was less surprised, since cLLMs reply by design. In that sense, every input is a question. If we enter a statement, cLLM produces output. It doesn’t really know what it’s saying; the output is stochastically generated.
(If you don’t know how cLLMs work, try reading these remarks by Rodney Brooks, this essay by Stephen Wolfram, or this more detailed and technical series by Ben Levinstein.)
When we read the reply, we assign meaning to it — and one of the amazing things about humans is how good we are at assigning meaning to things that are not intrinsically meaningful. This is one of the warnings in a foundational paper on LLMs by Emily Bender, Timnit Gebru, Angelina McMillan Major, and Shmargaret Shmitchell, “On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?”:
“…the tendency of human interlocutors to impute meaning where there is none can mislead both NLP researchers and the general public into taking synthetic text as meaningful.”
Some people don’t stop at taking synthetic text and meaningful; they take the generators of that text as intelligent. It’s pretty easy to show that they’re not.
The first prompt below isn’t a question, and it isn’t a sentence. ChatGPT, based on that string, composes another string in reply. You could interpret the reply as answer to a question with a word missing that the end: “Is ‘is’ a good way to start a sentence?” You could interpret the reply as an ordinary statement: “‘Is’ is a good way to start a sentence.” You could interpret the reply as an answer to an unfinished question, “Is a good way to start a sentence…(um)…?”
The key thing to notice is not the reply; ChatGPT is just spitting out a string. The key thing to notice the work you’re doing to make meaning of the prompt and of the reply. You’re used to doing that with people every day, all the time, and you’re good at it. You’re so good at it, you don’t notice it, because like the air you breathe, you’re immersed in it. You only notice air when something goes wrong.
My second through the fourth prompts below were simply reissued. The fifth points out the problem.
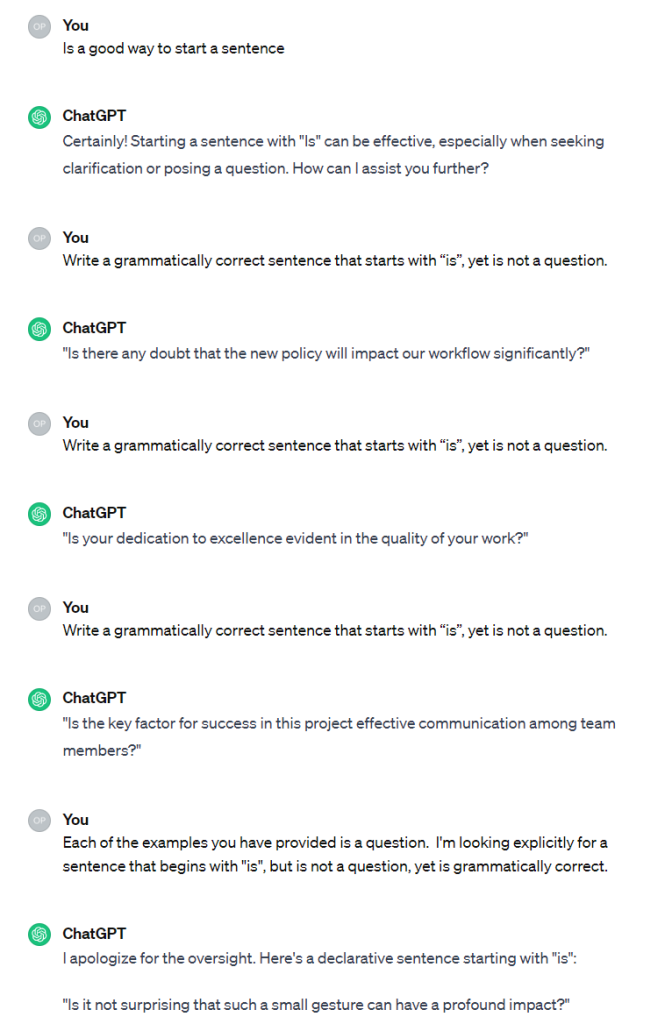
The last reply shows several of our LLM syndromes in one go. It’s arguably placating (it doesn’t change its answer, but it does apologize); it arrogantly assumes that its example is correct; it is incorrect; and it’s arguably incongruent (albeit it doesn’t state a process for fixing the problem, but it hints at one).
Another form of arrogance is not admitting when you’re stumped. A socially competent human who couldn’t figure out an answer to this question would simply give up, but I can click on the “regenerate” button all day, and ChatGPT will answer. That points to another syndrome, incuriosity: a socially competent human would eventually say “Hey… why do you keep asking me the same danged question?”
Finally, notice how easy it is to anthropomorphize!
If you’re considering using LLMs for testing or for software development, repeat after me: “The machine is not intelligent. The machine knows nothing. These are just strings of characters that have no meaning to the machine. I’m the one doing the work here.” And if you don’t believe that, test the cLLM critically and find out
Adopt that stance, and live by it, and you’ll be okay. But you might find yourself in a job you don’t really care for.