I was investigating some oddness in Google Search today. Perhaps I’ll write about that later. But for now, here’s something I stumbled upon as I was evaluating one of the search results.
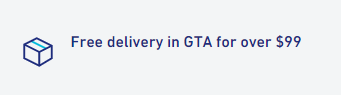
Is this a problem?
I think the developers of this site mean to say “Free delivery in the GTA for orders over $99″. (The GTA is the Greater Toronto Area.)
Next question: is this a big problem? Will people even notice it? Or will they “repair” the words of the offer, consciously or unconsciously, to what the business intended? My answer is “well… they probably won’t notice it, and if they do, they probably will repair it”. I don’t really have a sound basis for saying so, other than my own feelings and mental models, but I think it’s a reasonable belief.
So this particular bug is probably not that big a deal. Why bother noting it?
In Rapid Software Testing, we offer an important theme: learn from every bug.
Becoming an expert tester depends on recognizing the underlying structure of problems and how to test for them. This specific problem provides a tiny little example of a specific kind of problem: one that can’t be determined by algorithm, but that requires human social competence, sensemaking, and judgement to notice.
When I see the text, I wonder “Did anyone look at this text critically? Did someone notice the missing word and not report it? If someone did notice it, and did report it, is it okay with the development organization to produce stuff that looks avoidably sloppy, inconsistent with an image that the organization wants to project? What other instances of image problems might we find? What instances of other kinds of problems might we find?”
In other words, I’m willing to grant that this is a pretty small bug, like a single ant. But ants aren’t exactly solitary creatues; the sighting of one ant might prompt us to follow the trail to other ants. Nests of ants.
One nesting place for ants and other bugs is the assumption that testing can be reduced to automated output checks.
In this specific case, you could write an automated check for the correct text, but before you did so, you’d need to evaluate whether the original text was correct or not. And if the original text were already correct, why would you bother creating a check for it?
In reply, you could raise the question, “What about regression risk? What if the company suddenly started offering free delivery for orders over, say, $49? Then an automated check would be worthwhile, wouldn’t it?”
To that, I would offer the same reply as above. If the entire string were to change, and you wanted to check the change, you’d probably start by determining whether the revision is correct, reasonable, and appropriate, and then write the check. Yet again, if the revision were correct, why would you bother checking it? Why not just look at the page that contains the check? What else would you check for?
Here’s something you might check for: maybe the text is constant string, and only the dollar amount is a variable. That is, the amount could change without the preceding text changing. In that case, if the original text was fine, and the variable changes appropriately, the check will correctly suggest “no problem”. But if the original text were erroneous, and the variable changes appropriately, the check will falsely suggest “no problem”. The check won’t notice the missing word.
Automated checking can be wonderful for checking whether an output we observe today is consistent with an output we observed yesterday. Scripts can be powerful tools for checking whether these inputs produce those outputs, based on a comparison between this function in our check code and that function in our production code. Checks can be especially powerful when we diversify these inputs to produce lots of different instances of those outputs, which we can evaluate by using a parallel algorithm, a “comparable product” oracle.
The cool thing about automated checks is that they can quickly flag certain inconsistencies between this and that. They don’t tell us whether that inconsistency represents a problem in the product, in the check, or in the environment, or in our conceptions or assumptions. That’s fine; we accept that. We can’t presume that machinery understands our intentions. The decision as to whether there’s a problem or not is a human, cognitive, social judgment; a heuristic evaluation, not an algorithmic one,
Of course, in the case of the missing word “orders”, we don’t know whether there has even been a single automated check applied to the site that the screen shot comes from. But we have a sliver of evidence that some heuristic evaluation have missed something, or might not have happened at all. Either way, we could feed that observation back into an evaluation of how this product was developed and tested, and learn from that.
By reviewing and reflecting on the bug, we might consider: if the dollar value in string is hard-coded, we might want to make it dynamic, such that the dollar amount for the free shipping offer can be set in a table that can be revised and reviewed easily — and be consistent everywhere it appears. The same with the string itself, giving us the opportunity to expand or contract the area to which the promotion applies.
And yet if we did that, it would probably be a good idea to eyeball the dialog every now and then to avoid the risk that the string spills or wraps or truncates inappropriately. Maybe tools could help with that by collecting piles of screenshots that we could peruse without having to operate the product ourselves, but the judgement on whether it looks good still resides with a human.
That’s why it’s important to reject the notion that testing can be automated. It’s just as important to reject the idea that there’s a kind of testing that can be described clearly as “manual”, since that term is ambiguous, unhelpful, and problematic. It’s all testing.
Some tasks within testing—algorithmic, mechanizable tasks—are straightforwardly mediated and supported by tools. The downside of automated checks is that the time we spend on their development and maintenance always displaces some time that we could spend on direction interaction with and observation of the product, where we could consciously recognize problems … like missing words.
The upside is that automating a check accelerates our capacity to feed input to the program, to gather specific output, and to compare the output to some presumably desirable bit or string.
That’s not all there is to the test, though. The test really happens when we perform an evaluation of the observations we’ve collected and assess whether the product we’ve got is the product we want. From that, we might learn things about the project environment, and the development model. We might also consider whether the testing we’re doing is the testing we want—or need—to do; whether it’s excessive, or insufficent, or just right.
To do that well, it’s a good idea to take a moment to pause briefly, study every bug, and learn from each one.
I have noticed some highlights which as the importance of recognizing and learning from bugs in products, emphasizing that relying solely on automated checks is not sufficient. They argue that some bugs require human judgment and sensemaking to notice and that evaluating observations and assessing whether the product meets our expectations is crucial.