Over the last few blog posts, I’ve been focusing on oracles—means by which we could recognize a problem when we encounter it during testing. So far, I’ve talked about
- feelings and private mental models within internal, tacit experiences;
- consistency heuristics by which we can make inferences that help us to articulate why we think and feel that something is a problem;
- brief exchanges—tiny bursts of conferences—between people with collective tacit knowledge, and shared feelings and mental models;
- data sets and tools that produce visualizations that are explicit—things that we can point to—references that we can observe, analyze and discuss
Most of the examples I’ve shown so far involve applying oracles retrospectively—seeing a problem and responding to it, starting in the top left corner of this diagram.
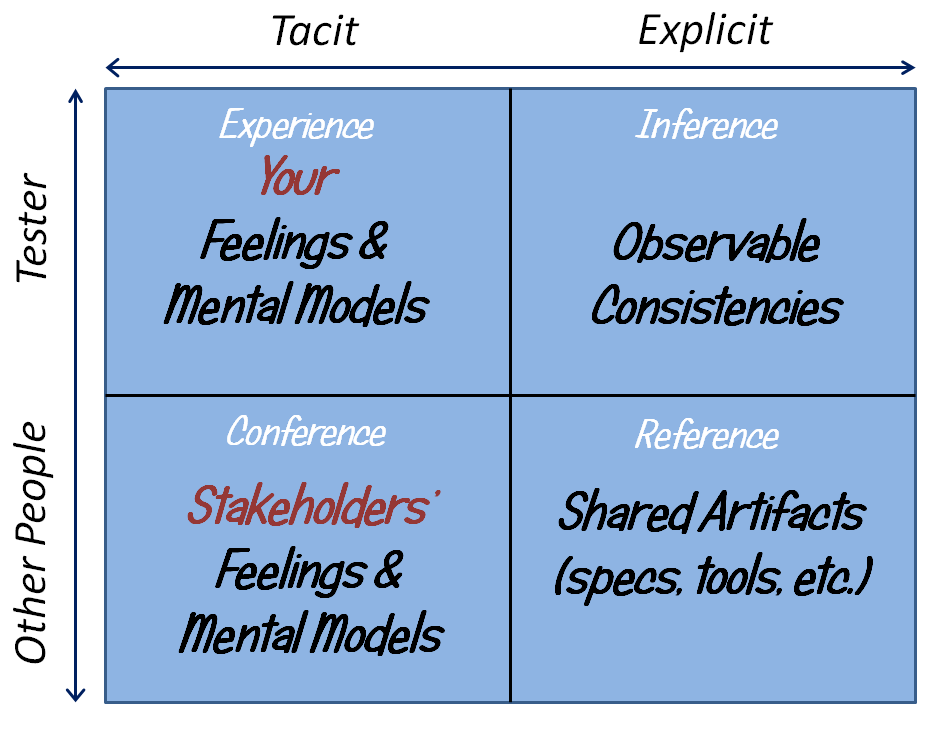
But maybe experience with the product isn’t the only place we could start. Maybe we could start in the bottom right of the table, with tools.
Let’s begin by asking ourselves why we can’t see instantly when things go wrong with software. Why aren’t all bugs immediately obvious? The first-order answer is itself obvious: software is invisible. It’s composed, essentially, of electrons running through sand, based on volumes of instructions written by fallible humans, and whatever happens takes place inside tiny boxes whose contents and inner structures are obscure to us. That answer should remind us to presume that many bugs are by their nature hidden and subtle. Given that, how can we make bugs obvious? If we wish to identify something that we can’t perceive with unaided observation, we’ll need internal or external instrumentation. If we think and talk about tool support to reveal bugs, we might choose to develop it more often, and learn to build it wisely and reliably.
With those facts in front of us, how might we prepare ourselves to anticipate and to notice problems, with the help of tools to extend our observational powers?
1) Learn the product. That process may—indeed, should, if possible—start even before the product has been built; we can learn about the product and people’s ideas for it as it is being designed. We become more powerful testers as we add to our knowledge of the product, the problem it is intended to solve, and the conditions under which it will be used. This is not just an individual process, but a social process, a team process. A development group not only builds a product; it learns to build a product as it tries to build the product. Both kinds of learning continue throughout the project.
2) As we learn the product, consider risks. What could go wrong? Considering risks may also start before the product has been built, is also a collaborative process, and is also continuous. For instance…
- A system may not be able to fulfill the user’s task. It may not produce the desired result; some feature or function may be missing. It may not do the right things, or it may do the right things in the wrong way. It may do the wrong things. That is, the system might be have a problem related to capability.
- A program may exhibit inconsistent behaviour over time. Outputs may vary in undesirable ways. Functions or features may be unavailable from time to time. Something that works in one version may fail to work in the next. That is, the system might have a problem with reliability.
- A system may be vulnerable to attack or manipulation, or it may expose data to the world that should be kept private. It may permit records to be changed or altered. That is, the system might have a problem related to security.
- A system might run into difficulty when overloaded or starved of resources. The system might be slow to respond even under normal conditions. That is, the system may have problems with performance.
- A system may have trouble handling more complex processing, larger amounts of data, or larger numbers of users than could be supported by the original design. That is, the system may have problems related to scalability.
- Something that should be present might be absent; or something that should be absent might be present. Files might be missing from the distribution, or proprietary files might be included inadvertently. Registry entries or resource files might not include appropriate configuration settings. The uninstaller might leave rubbish lying around, zap data that the user wants to retain, or uninstall components of other programs. That is, the system may have problems related to installability.
This set of examples is by no means complete. There’s a long list of ways in which users might obtain value from a product, and practically an infinite list of ways things that could go wrong. Although machinery cannot evaluate quality, specific conditions within these quality criteria in particular are amenable to being checked by mechanisms either external or internal to the program. Those checks can direct human attention to those conditions. So…
3) As we learn about the product and what can go wrong, consider how a check might detect something going wrong. One rather obvious way to detect a problem would be to imagine a process that the product might follow, drive the product with a tool, and then check if the process comes to an end with a desirable result. For extra points, have the tool collect output produced by the product or some feature within it, and then have the tool check that data for correctness against some reference. But we could also use checking productively by
- examining data at intermediate states, as it is being processed, and not only at output time;
- evaluating components of the product to see if any are missing, or the wrong version, or superfluous;
- identifying platform elements—systems or resources upon which our product depends—and their attributes, including their versions and their capabilities;
- observing the environment in which the program is running, to see if it changes in some detectable and significant way;
- monitoring and inspecting the system to determine when it enters some state, when some event occurs, or when some condition is fulfilled;
- timing processes within the system that must be completed within known, specific limits.
When something noteworthy happens, we have the option of either logging the incident or being notified immediately by some kind of alert or alarm.
Checking of this kind is a special case of something more general: bringing problems to our awareness and attention. Again, machinery cannot evaluate quality or recognize threats to value, so a check requires us to anticipate and encode each specific condition to be checked, and, after the check, to interpret its outcome whether red or green.
Moreover, to match the value of checks with the cost of developing and maintaining them, and to avoid being overwhelmed by having to interpret the results from automated checks, we must find ways to decide what’s likely to be interesting and not so interesting. Using tools to help us learn about that is the subject of the next post.
[…] Blog: Oracles from the Inside Out, Part 7: References as Checks – Michael Bolton – http://www.developsense.com/blog/2015/10/oracles-from-the-inside-out-part-7/ […]