In the last installment, we ended by asking “Once the tester has learned something about the product, how can you focus a tester’s work without over-focusing it?
I provided some examples in Part 4 of this series. Here’s another: scenario testing. The examples I’ll provide here are based on work done by James Bach and Geordie Keitt several years ago. (I’ve helped several other organizations apply this approach much more recently, but they’re less willing to share details.)
The idea is to use scenarios to guide the tester to explore, experiment, and get experience with the product, acting on ideas about real-world use and about how the product might foreseeably be misused. It’s nice to believe that careful designs, unit testing, BDD, and automated checking will prevent bugs in the product — as they certainly help to do — but to paraphrase Gertrude Stein, experience teaches experience teaches. Pardon my words, but if you want to discover problems that people will encounter in using the product, it might be a good idea to try using the damned product.
The scenario approach that James and Geordie developed uses richer, more elaborate documentation than the one- to three-sentence charters of session-based test management. One goal is to prompt the tester to perform certain kinds of actions to obtain specific kinds of coverage, especially operational coverage. Another goal is to make the tester’s mission more explicit and legible for managers and the rest of the team.
Preparing for scenario testing involves learning about the product using artifacts, conversations, and preliminary forms of test activity (I’ve given examples throughout this series, but especially in Part 1). That work leads into developing and refining the scenarios to cover the product with testing.
Scenarios are typically based around user roles, representing people who might use the product in particular ways. Create at least a handful of them. Identify specifics about them, certainly about the jobs they do and the tasks they perform. You might also want to incorporate personal details about their lives, personalities, temperaments, and conditions under which they might be using the product.
(Some people refer to user roles as “personas”, as the examples below do. A word of caution over a potential namespace clash: what you’ll see below is a relatively lightweight notion of “persona”. Alan Cooper has a different one, which he articulated for design purposes, richer and more elaborate than what you’ll see here. You might seriously consider reading his books in any case, especially About Face (with Reimann, Cronin, and Noessel) and the older The Inmates are Running the Asylum.)
Consider not only a variety of roles, but a variety of experience levels within the roles. People may be new to our product; they may be new to the business domain in which our product is situated; or both. New users may be well or poorly trained, subject to constant scrutiny or not being observed at all. Other users might be expert in past versions of our products, and be irritated or confused by changes we’ve made.
Outline realistic work that people do within their roles. Identify specific tasks that they might want to accomplish, and look for things that might cause problems for them or for people affected by the product. Problems might take the form of harm, loss, or diminished value to some person who matters. Problems might also include feelings like confusion, irritation, frustration, or annoyance.
Remember that use cases or user stories typically omit lots of real-life activity. People are often inattentive, careless, distractable, under pressure. People answer instant messages, look things up on the web, cut and paste stuff between applications. They go outside, ride in elevators, get on airplanes and lose access to the internet; things that we all do every day that we don’t notice. And, very occasionally, they’re actively malicious.
Our product may be a participant in a system, or linked to other products via interfaces or add-ins or APIs. At very least, our product depends on platform elements: the hardware upon which it runs; peripherals to which it might be connected, like networks, printers, or other devices; application frameworks and libraries from outside our organization; frameworks and libraries that we developed in-house, but that are not within the scope of our current project.
Apropos of all this, the design of a set of scenarios includes activity patterns or moves that a tester might make during testing:
- Assuming the role or persona of a particular user, and performing tasks that the user might reasonably perform.
- Considering people who are new to the product and/or the domain in which the product operates (testing for problems with ease of learning)
- Considering people who have substantial experience with the product (testing for problems with ease of use).
- Deliberately making foreseeable mistakes that a user in a given role might make (testing for problems due to plausible errors).
- Using lots of functions and features of the product in realistic but increasingly elaborate ways, and that trigger complex interactions between functions.
- Working with records, objects, or other data elements to cover their entire lifespan: creating, revising, refining, retrieving, viewing, updating, merging, splitting, deleting, recovering… and thereby…
- Developing rich, complex sets of data for experimentation over periods longer than single sessions.
- Simulating turbulence or friction that a user might encounter: interruptions, distractions, obstacles, branching and backtracking, aborting processes in mid-stream, system updates, closing the laptop lid, going through a train tunnel…
- Working with multiple instances of the product, tools, and/or multiple testers to introduce competition, contention, and conflict in accessing particular data items or resources.
- Giving the product to different peripherals, running it on different hardware and software platforms, connecting it to interacting applications, working in multiple languages (yes, we do that here in Canada).
- Reproducing behaviours or workflows from comparable or competing products.
- Considering not only the people using the product, but the people that interact with them; their customers, clients, network support people, tech support people, or managers.
To put these ideas to work at ProChain (a company that produces project management software), James and Geordie developed a scenario playbook. Let’s look at some examples from it.
The first exhibit is a one-page document that outlines the general protocol for setting up scenario sessions.
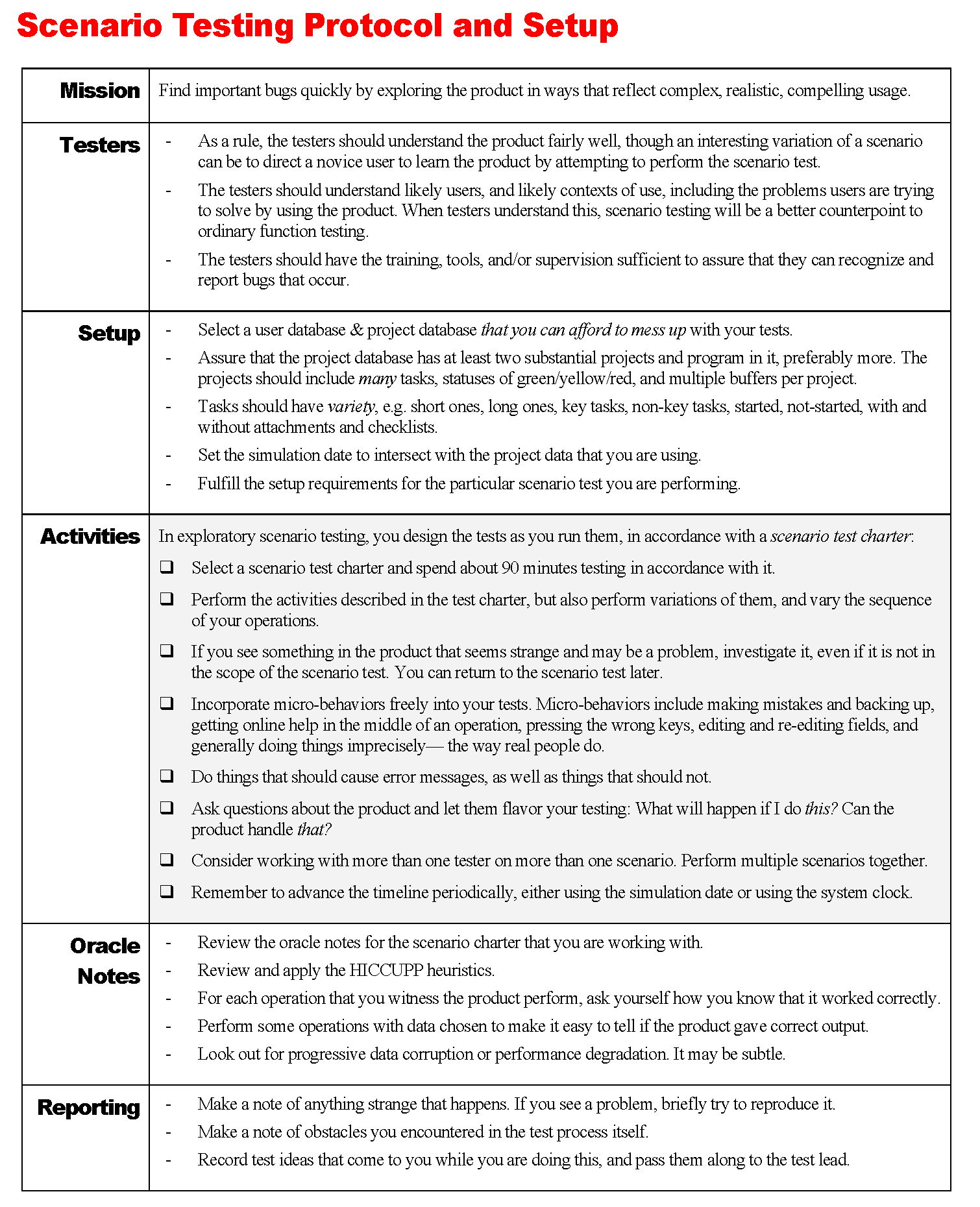
This document is an overview that applies to every session. It is designed primarily to give managers and supporting testers a brief overview of the process and and how it should be carried out. (A supporting tester is someone who is not a full-time tester, but is performing testing under the guidance and supervision of a responsible tester — an experienced tester, test lead, or a test manager. A responsible tester is expected to have learned and internalized the instructions on this sheet.) There are general notes here for setting up and patterns of activities to be performed during the session.
Testers should be familiar with oracles by which we recognize problems, or should learn about oracles quickly. When this document was developed, there was a list of patterns of consistency with the mnemonic acronym HICCUPP; that’s now FEW HICCUPPS. For any given charter, there may be specific consistency patterns, artifacts, documents, tools, or mechanisms to apply that can help the tester to notice and describe problems.
Here’s an example of a charter for a specific testing mission:
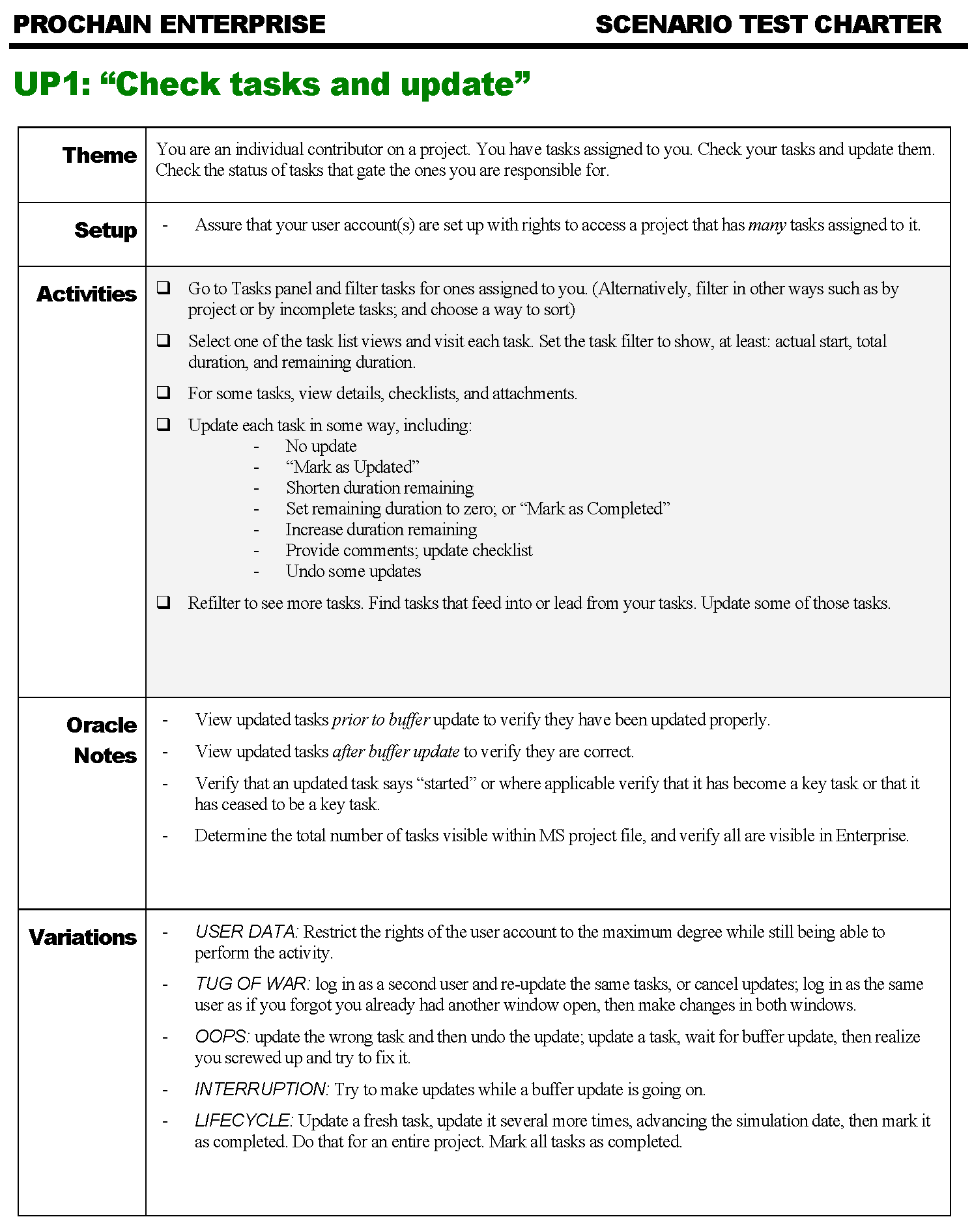
The Theme section outlines the general purpose of the session, as a one- to three- line charter would in session-based test management. The Setup section identifies anything that should be done specifically for this session.
Note that the Activities section offers suggestions that are both specific and open. Openness helps to encourage variation that broadens coverage and helps to keep the tester engaged (“For some tasks…”; “…in some way,…”). Specificity helps to focus coverage (“set the task filter to show at least…”, with attention towards the set of different ways to update tasks).
The Oracles section identifies specific ways for the tester to look for problems, in addition to more general oracle principles and mechanisms. The Variations section prompts the tester to try ideas that will introduce turbulence, increase stress, or cover more test conditions.
A debrief and a review of the tester’s notes after the session helps to make sure that the tester obtained reasonable coverage — or helps to explain what might have got in the way of that.
Here’s another example from the same project:
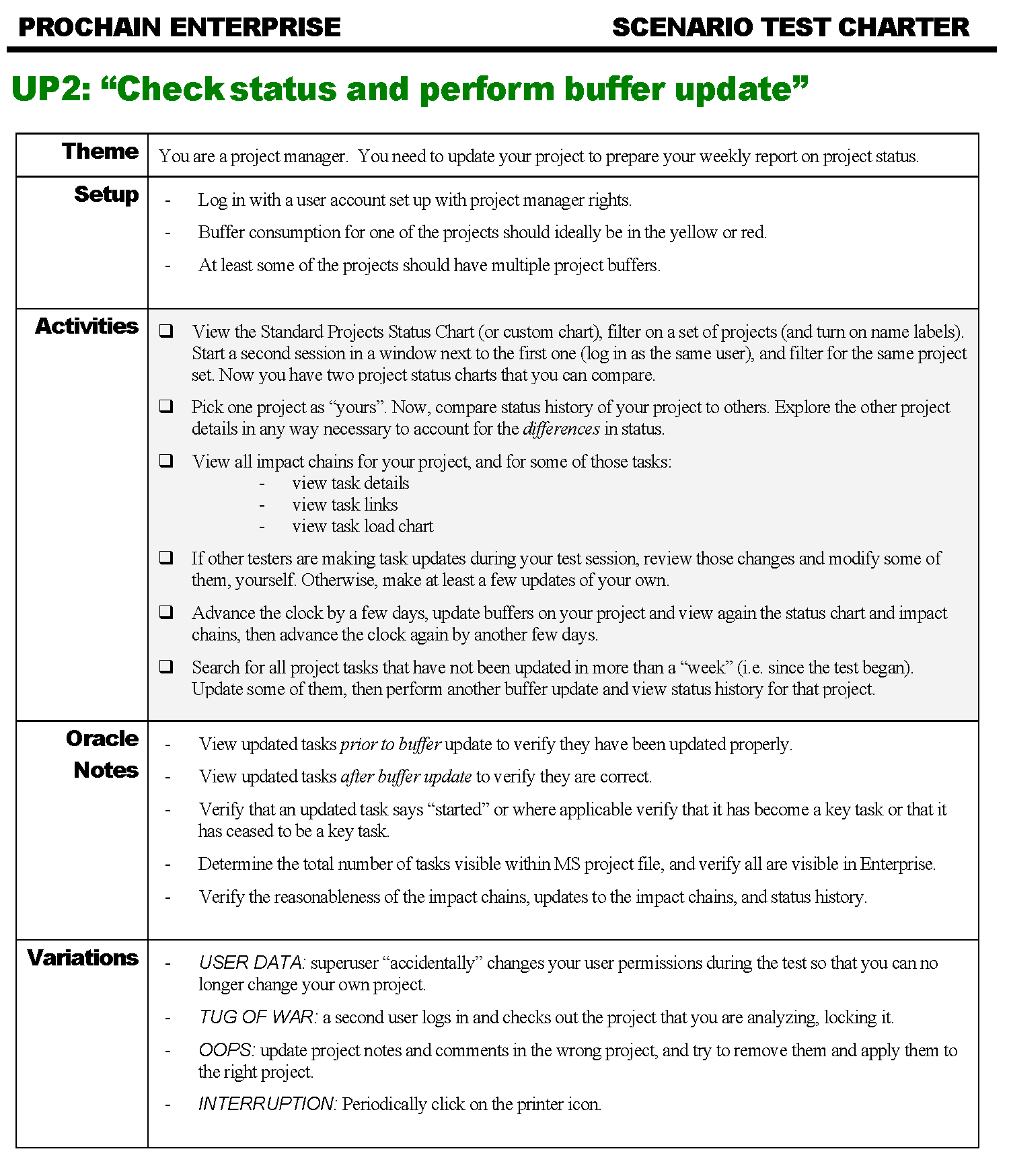
Here the tester is being given a different role, which requires a different set of access rights and a different set of tasks. In the Activities and Variations section, the tester is encouraged to explore and to put the system into states that cause conflicts and contention for resources.
Creating session sheets like these can be a lot more fun and less tedious than typing out instructions in formally procedurally scripted test cases. Because they focus on themes and test ideas, rather than specific test conditions, the sheets are more compact and easier to review and maintain. If there are specific functions, conditions, or data values that must be checked, they can be noted directly on the sheet — or kept separately with a reference to them in the sheet.
The sheets provide plenty of guidance to the tester while giving him or her freedom to vary the details during the session. Since the tester has a general mission to investigate the product, but not a script to follow, he or she is also encouraged and empowered to follow up on anything that looks unusual or improper. All this helps to keep the tester engaged, and prevents him or her from being hypnotized by a script full of someone else’s ideas.
You can find more details on the development of the scenarios in the section “PCE Scenario Testing” in the Rapid Software Testing Appendices.
Back in our coaching session, Frieda once again picked up the role of the test-case-fixated manager. “If we don’t give them test cases, then there’s nothing to look at when they’re done? How will we know for sure what the tester has covered?”
It might seem as though a list of test cases with check marks beside them would solve the accountability problem — but would it? If you don’t trust a tester to perform testing without a script, can you really trust him to perform testing with one?
There are lots of ways to record testing work: the tester’s personal notes or SBTM session sheets, check marks and annotations on requirements and other artifacts, application log files, snapshot tools, video recording… Combine these supporting materials with a quick debriefing to make sure that the tester is working in professional way and getting the job done. If the tester is new, or a supporting tester, increase training, personal supervision and feedback until he or she gains your trust. And if you still can’t bring yourself to trust them, you probably shouldn’t have them testing for you at all.
Frieda, still in character, replied “Hmmm… I’d like to know more about debriefing.” Click here (not on the link below; that’s something different) for the next post in this series!
[…] Breaking the Test Case Addiction (Part 6) Written by: Michael Bolton […]
Thanks for the thought provoking series Micheal. And the test framing article linked in part 1 was excellent.
Michael replies: Thank you for the kind words.
What are your thoughts on a strategy to facilitate continuous deploy and automation? I can see management gaining comfort from detailed test cases being converted to equivalent automation. What do you recommend to facilitate portability of requirements to those doing automation, confidence in quality coverage, and management buy off?
I want to give you a chance to answer this question for yourself by offering a reframe.
Instead of a strategy to facilitate continuous deployment and automation, my first step would be to ask what problem we’re trying to solve with continuous deployment and automation.
Automation is neither a goal nor something that you do. It’s a means by which you do something; not an end in itself. It’s an element in your strategy for doing something desirable (or maybe, if you decide it’s not helpful, it’s not an element in your strategy at all). Similarly, “facilitating continuous deployment” isn’t a goal in and of itself; it may be a means of accomplishing some part of your mission. This is important, because you don’t want to distract yourself from the real goal.
And what might that real goal be? It seems to me that management’s primary goal&mdash:for testers, at least—is making sure that management and the developers are quickly aware of problems that threaten the value of the product. Note that this is NOT the same as comforting management or building confidence. That’s not our job as testers, in my view. Our job is to learn about the product, with the goal of finding problems, and finding instances where confidence might be unwarranted.
So start from this premise: how does the ability to build quickly (including automated checking) help us to study the product more quickly (when some quick checking is all it needs) and more deeply (when we’re looking for hidden, rare, subtle, intermittent, or emergent bugs?
Then, for any particular idea or tool or process element that you might apply to answering that question, ask these ones:
What will happen if we do this?
What will happen if we don’t?
What won’t happen if we do this?
What won’t happen if we don’t?
Think that through, and if you have more questions, feel free to ask here.
Thanks again for all the work to share these valuable insights, especially on how to communicate effectively up the management chain.
You’re welcome. Thank you.
Great point on the real goal. For my employer, CD is being done with some services. The effect has been higher developer morale, faster long-term feature velocity, fewer escape bugs, and ability to patch quickly. Testers verify features and probe edge cases, but the checking is handled by automation and production alerts.
For non-CD components there is a 2-week release cycle, which requires a pre-release manual checking phase.
So if we go through the above exercise, here’s what I come out with
What will happen if we [create detailed test cases]?
Detailed test cases would communicate coverage requirements for automation
What will happen if we don’t [create detailed test cases]?
We’ll have to find some other way to communicate the manual checking knowledge to team members who can do automation, or remain on 2-week deploys (and eventually slip to 3-week deploys as the feature set grows)
What won’t happen if we [create detailed test cases]?
We won’t have to pair up with new testers for checking training, they can follow the checklist until the automation is in place, or the checking could be out/crowd-sourced.
Compared to now, there won’t be as much creative or informed checking.
What won’t happen if we don’t [create detailed test cases]?
We won’t have to maintain a large body of test cases (But once automation occurs the authoritative details are in code, and won’t be necessary in test case prose)
I’m sure I’m missing some tradeoffs, have you seen organizations significantly reduce or eliminate a pre-release checking without test cases?
Michael replies: I’m now beginning to believe that there is an element missing from the four questions. The problem that I’m seeing right now is rooted to the “we have to” business, but in general, it seems to me that it would be a good idea to subject each reply to some critical thinking. James Bach and I have a heuristic for triggering critical thinking: Huh? Really? And? So?
For instance: The reply to “What will happen if we don’t [create detailed test cases]?” begins with “We’ll have to find some other way to communicate the manual checking knowledge…” Huh? Let me look at that again. Wait… what is “manual checking”? Is manual checking “checking without tools”?
It seems to mean what it says, so let’s move to: Really?
Really? You have to communicate manual checking knowledge? What if automated checks were part of the programming process? The fastest test you can perform is the one you don’t have to perform. The fastest check you can run is the check you don’t have to run. The fastest test case that you can write is the one you don’t have to write, because you know enough already to train your attention on riskier things that you don’t know.
Why do manual checking at all? One reply could be “because the programmers aren’t checking their own code, nor are they checking each other’s — and they’re going quickly enough that they’re making lots of mistakes that could be caught with checks of their own”.
And? Is the goal automation? Or is the goal to find problems in the product that might threaten its value?