In the previous post, I gave an example of the happy (and, alas, rare) circumstance in which the programmer and I share models and feelings, such that the programmer becomes aware of a problem I’ve found without my being explicit about it. That is, on this table, I can go directly from top-left, where I experience the problem, to conference in the bottom left, where awareness of that problem has been successfully conveyed to someone else.
More often than not, my testing client will not recognize the meaning and significance of the problem immediately in the same way that I do. My awareness of a problem tends to start with a feeling. To impart my feeling of a problem successfully to others, most of the time I must move from my tacit, internal, and emotional reaction about it, and develop an explicit and rational description of the problem. That move often begins with framing the problem in terms of logical inferences, based on an undesirable inconsistency between my observation of the product and my understanding of some desirable principle. (An inference is conclusion that we arrive at by a line of reasoning, in which we make logical connections between facts. Inference is also an activity—the process of making those connections.) In the diagram, that’s a move from the upper left to the upper right, from a tacit feeling to an observable and explicit inconsistency; from experience to inference.
I’ve been testing a version of Adobe Acrobat. In its File / Properties dialog, there’s a metadata field called “Keywords”. I enter some data using Perlclip’s counterstring feature (a counterstring is a string that allows you to see its own length easily).
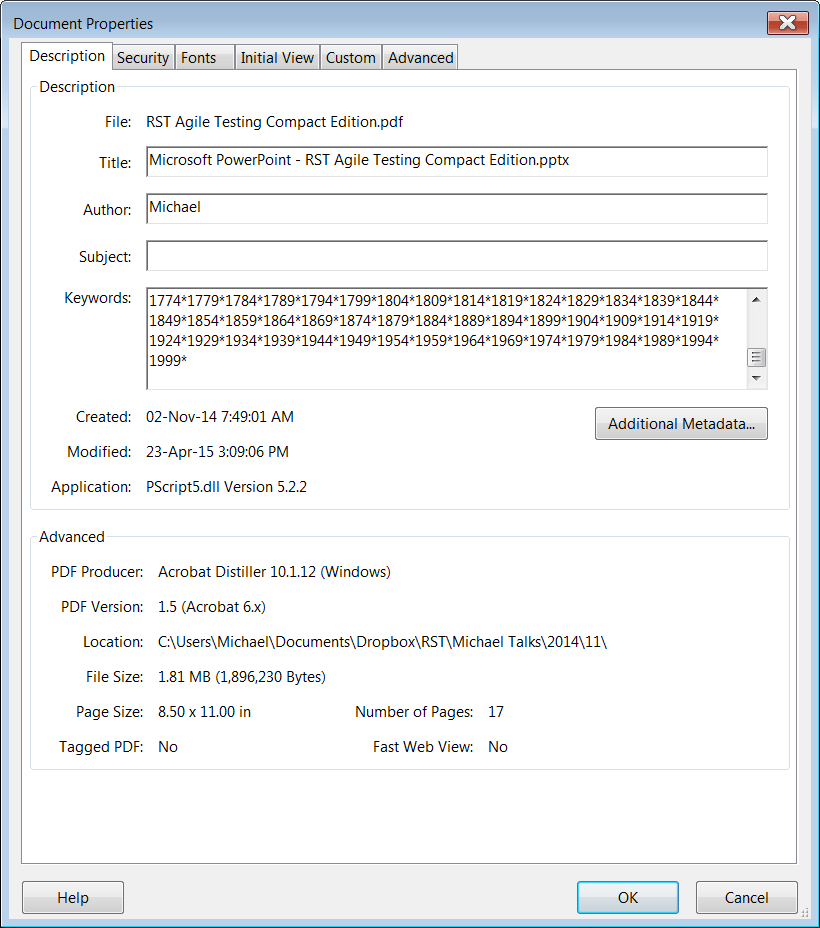
I observe that this field appears to be limited to a maximum of 1,999 characters. I try typing beyond this apparent limit, and nothing happens. When I click on the “Additional Metadata” button a new dialog appears. That dialog also has a “Keywords” field; the text that I entered into the previous dialog is observable there too. The field looks a little different, though. I experience a feeling of curiosity, and make an inference that something else might be different here. I move to the cursor into the Keywords field, and press Ctrl-End. Then I try to enter some text.
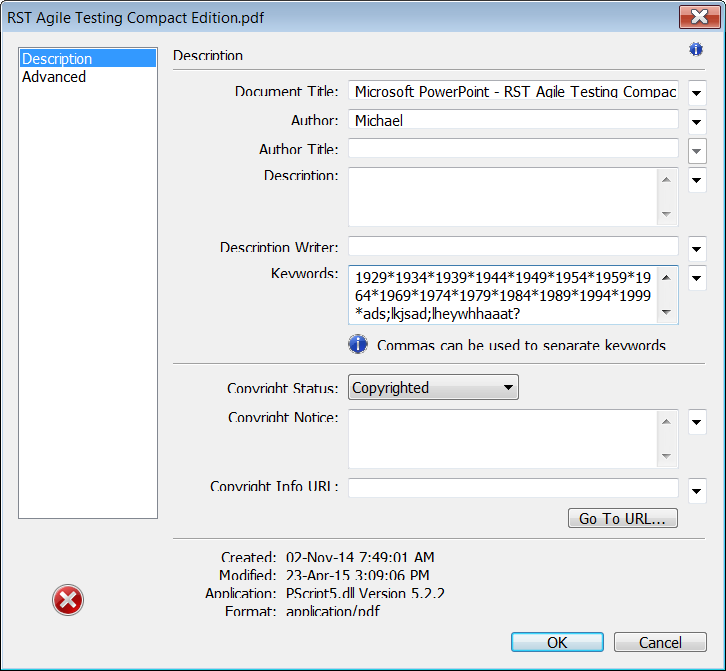
I observe that I’m able to enter more than I was able to enter into the “Keywords” field in the previous dialog; the limit appears to be broken. That’s interesting. I paste the counterstring from Perlclip, and discover the the limit is 30,000 characters.
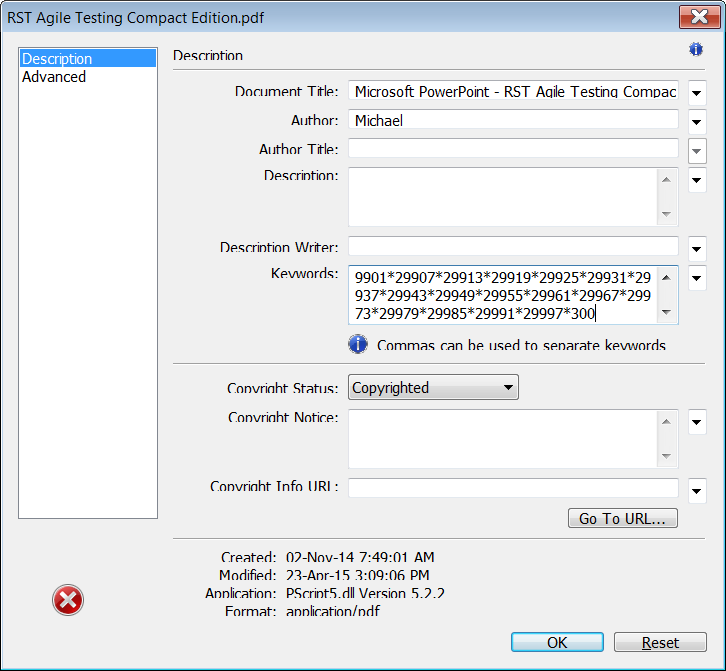
When I dismiss the Additional Metadata dialog, the original File / Properties dialog shows the 30,000-character string. I experiment a little more, and find I can delete characters from that string and replace them with new ones; there’s no longer a 1,999-character limit. Hmmm.
I go back to the Additional Metadata dialog, and delete some text from the Keywords field. I dismiss the dialog, and discover my changes have been reflected in the File/Properties/Keyword field. As before, I can edit what’s there, but the limit is now the length of string that was in the Additional Metadata dialog; less than 30,000, but more than 1,999.
This is all a little surprising, but is this a problem? I refer to my feelings and make some inferences, based on principles related to consistencies and inconsistencies.
In one dialog, there appears to be an enforced limit of 1,999 characters for the Keywords field; in another, the limit is 30,000 characters. I’m surprised and little confused, because the product appears to be inconsistent with itself. I don’t understand why all this should be so; the product is behaving in a way that is inconsistent with my ability to explain it. I infer that wherever there’s a limit, someone had some purpose in setting it. I don’t have access to the programmer’s or designer’s intentions at the moment, but whichever limit someone intended, the product seems inconsistent with one of them—inconsistent with purpose. I’ve seen problems like this before—in some cases, data from one field overwrites data in another, corrupting the file or providing the opportunity for a buffer-overflow attack—so I can infer some risks based on the product being consistent with patterns of familiar problems.
In Rapid Testing, we’ve collected these and several other principles by which we can make inferences about problems in the product; you can find our current list of these oracles here. Armed with oracles in the form of consistency heuristics—principles and inferences about them—, I’ve got more—much more—than “huh?” or “euuugh!” available to me when I’m relating the problem to my client.
Some testers habitually report problems in terms of a “defect”, “actual result” and an “expected result”. This kind of templatized reporting often seems imprecise and even a little lame to me, for reasons that I set out here and here. It’s premature and presumptuous of me even to think of this as a defect, never mind making such a claim in a formal report. Testers confuse “expectation” with “desire”; something can be desirable or undesirable regardless of what we expected from it. Neither expectations nor desires are absolutes; they’re relative to some person(s), and based on specific models, quality criteria, and principles. So, rather than using the tired “expected result/actual result” pattern, try providing your observation of a problem and the inconsistency principle that gives warrant to your belief that it is a problem.
Some of the oracle principles can be applied fairly directly and immediately to a reasonably solid inference. For example, I know tacitly that Adobe’s business is all about rendering text and images beautifully on paper and on screens, so it seems to me that the font rendering issue (as I noted in an earlier post, and as you can see above in the Additional Metadata dialog) is inconsistent with an image that Adobe might reasonably want to project. Some problems, though, are more easily noticed or described with the help of some medium—a tool or an artifact based on and representing an explicit, shared model; something that we can point to; a reference. We’ll talk about that in the next post in this series.
You demonstrated in a great way how tacit knowledge, the feeling that there might be a problem, is made explicit by a cognitive process (inference) and the use of Oracles to recognize a problem.
In the inference process a tester uses heuristics, rules of thumb, shortcuts in his brain. He is trying to make sense of the world and finding a solution or making sense of stuff he does not understand. You showed that with the example of the inconsistency in the enforced character limit.
What I missed however is that during this cognitive process every tester is biased, where bias is the gap between our reasoning (heurstic) and how whe ought to have reasoned.
Being aware of your own fallacies helps testers in maturing their critical thinking.
To me knowing that I am biased and understanding my fallacies, helps me in my conference with developers. A lot of developers I know value testers that do not jump to conclusions or make statements that cannot be substantiated. Tester that give insight in the product with good reasoning are highly appreciated.
Therefore as we are all biased in many ways, Bias in itself could be an oracle for the inconsistencies in our own reasoning.
Do you see bias as an oracle?
Michael replies: If something affords you the opportunity to recognize a problem, it’s an oracle. I’m skeptical that biases do that across the board, and I’m skeptical that a bias is sufficiently specific to be cited as an oracle. My skepticism about the quality of a product (or an idea) helps me to recognize problems, but that sounds vague somehow.