There has been a flurry of discussion about estimation on the net in the last few months.
- Ward Cunningham tweeted, “Estimating is the non-problem that know-nothings spent decades trying to solve.”
- Pradeep Soundararajan wrote a long blog post on test effort estimation.
- A fellow named Nathaniel posted an interesting perspective on successful estimates on the Terralien Web site.
- Jens Schauder posted 8 Reasons Why The Estimates Are Too Low.
- Andre Dhondt weighed in more recently with Estimation Causes Waste, Slack Creates Value. (Actually I disagree. Slack doesn’t create value, but does add something to favourable conditions in which value can be created. An appropriate amount of slack provides opportunity to reduce threats to value.)
All this reminded me to post the results of some number-crunching experiments that I started to do back in November 2009, based on a thought experiment by James Bach. That work coincided with the writing of Swan Song, a Better Software column in which I discussed The Black Swan, by Nassim Nicholas Taleb.
A Black Swan is an improbable and unexpected event that has three characteristics. First, it takes us completely by surprise, typically because it’s outside of our models. Taleb says, “Models and constructions, those intellectual maps of reality, are not always wrong; they are wrong only in some specific applications. The difficulty is that a) you do not know beforehand (only after the fact) where the map will be wrong, and b) the mistakes can lead to severe consequences. These models are like potentially helpful medicines that carry random but very severe side effects.”
Second, a Black Swan has a disproportionately large impact, in contrast to the many rare and surprising events that happen and that aren’t such a big deal. Black Swans can destroy wealth, property, or careers—or create them. A Black Swan can be a positive event, even though we tend not to think of them as such.
Third, after a Black Swan, people have a tendency to say that they saw it coming. They make this claim after the event because of a pair of inter-related cognitive biases. Taleb calls the first epistemic arrogance, an inflated sense of knowing what we know. The second is the narrative fallacy, our tendency to bend a story to fit with our perception of what we know, without validating the links between cause and effect.
It’s easy to say that we know the important factors of the story when we already know the ending. The First World War was a Black Swan; September 11, 2001 was a Black Swan; the earthquake in Haiti, the volcano in Iceland, and the Deepwater Horizon oil spill in the Gulf of Mexico were all Black Swans. (The latter was a white swan, but it’s now coated in oil, which is the kind of joke that atracygnologists like to make). The rise of Google’s stock price after it went public was a Black Swan too. (You’ll probably meet people who claim that they knew in advance that Google’s stock price would explode. If that were true, they would have bought stock then, and they’d be rich. If they’re not rich, it’s evidence of the narrative fallacy in action.)
I think one reason that projects don’t meet their estimates is that we don’t naturally consider the impact of the Black Swan. James introduced me to a thought experiment that illustrates some interesting problems with estimation.
Imagine that you have a project plan in front of you. For estimation’s sake, you break it down into really fine-grained detail, such that each task would take one hour. The entire project decomposes into one hundred tasks, so your project should take 100 hours.
Suppose also that you estimated extremely conservatively, such that half of the tasks (that is, 50) are actually accomplished in half an hour, instead of an hour. Let’s call these Stunning Successes. 35% of the tasks are on time; we’ll called them Regular Tasks.
15% of the time, you encounter some bad luck.
- Eight tasks, instead of taking an hour, take two hours. Let’s call those Little Slips.
- Four tasks (one in 25) end up taking four hours, instead of the hour you thought they’d take. There’s a bug in some library that you’re calling; you need access to a particular server and the IT guys are overextended so they don’t call back until after lunch. We’ll call them Wasted Mornings.
- Two tasks (one in fifty) take a whole day, instead of an hour. Someone you were depending on for that hour has to stay home to mind a sick kid. Now, to get the job done, you have spend a whole day to figure things out on your own. Those we’ll call Lost Days.
- One task in a hundred—just one—takes two days instead of just an hour. A library developed by another team is a couple of days late; a hard drive crash takes down a system and it turns out there’s a Post-It note jammed in the backup tape drive; one of the programmers has her wisdom teeth removed (all these things have happened on projects that I’ve worked on). These don’t have the devastating impact of a Black Swan; they’re like baby Black Swans, so let’s call them Black Cygnets.
| Number of tasks | Type of task | Duration | Total (hours) |
|---|---|---|---|
| 50 | Stunning Success | 0.50 | 25 |
| 35 | On Time | 1.00 | 35 |
| 8 | Little Slip | 2 | 16 |
| 4 | Wasted Morning | 4 | 16 |
| 2 | Lost Day | 8 | 16 |
| 1 | Black Cygnet | 16 | 16 |
| 100 | 124 |
That’s right: the average project, based on the assumptions above, would come in 24% late. That is, you estimated it would take two and a half weeks. In fact, it’s going to take more than three weeks. Mind you, that’s the average project, and the notion of the “average” project is strictly based on probability. There’s no such thing as an “average” project in reality and all of its rich detail. Not every project will encounter bad luck—and some projects will run into more bad luck than others.
So there’s a way to modeling project like this, and it can be a lot of fun. Take the probabilities above, and subject them to random chance. Do that for every task in the project, then run a lot of projects. This shows you what can happen on projects in a fairly dramatic way. It’s called a Monte Carlo simulation, and it’s an excellent example of exploratory test automation.
I put together a little Ruby program to generate the results of scenarios like the one above. The script runs N projects of M tasks each, allows me to enter as many probabilities and as many durations as I like, puts the results into an Excel spreadsheet, and graphs them. Naturally, I found and fixed a ton of bugs in my code as I prepared this little project. But I also found bugs in Excel, including some race-condition-based crashes, API performance problems, and severely inadequate documentation. Ain’t testing fun?
For the scenario above, I ran 5000 projects of 100 randomized tasks each. Based on the numbers above, I got these results:
| Average Project | 123.83 hours |
| Minimum Length | 74.5 hours |
| Maximum Length | 217 hours |
| On time or early projects | 460 (9.2%) |
| Late projects | 4540 (90.8%) |
| Late by 50% or more | 469 (9.8%) |
| Later by 100% or more | 2 (0.9%) |
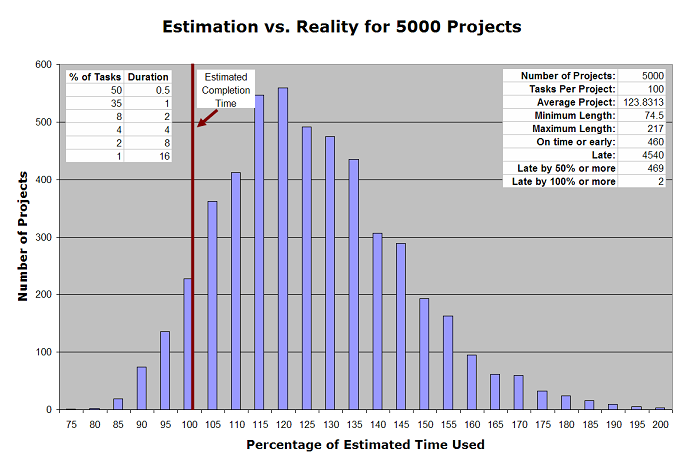
Here are some of the interesting things I see here:
- The average project took 123.83 hours, almost 25% longer than estimated.
- 460 projects (or fewer than 10%) were on time or early!
- 4540 projects (or just over 90%) were late!
- You can get lucky. In the run I did, three projects were accomplished in 80 hours or fewer. No project avoided having any Wasted Mornings, Lost Days, or Black Cygnets. That’s none out of five thousand.
- You can get unlucky, too. 469 projects took at least 1.5 times their projected time. Two took more than twice their projected time. And one very unlucky project had four Wasted Mornings, one Lost Day, and eight Black Cygnets. That one took 217 hours.
This might seem to some to be a counterintuitive result. Half the tasks took only half of the time alloted to them. 85% of the tasks came in on time or better. Only 15% were late. There’s a one-in-one-hundred chance that you’ll encounter a Black Cygnet. How could it be that so few projects came in on time?
The answer lies in asymmetry, another element of Taleb’s Black Swan model. It’s easy to err in our estimates by, say, a factor of two. Yet dividing the duration of a task by two has a very different impact from multiplying the duration by two. A Minor Victory saves only half a Regular Task, but a Little Slip costs two whole Regular Tasks.
Suppose you’re pretty good at estimation; you don’t underestimate too often. 20% of the tasks came in 10% early (let’s call those Minor Victories). 65% of the tasks come right on time (Regular Tasks). That is, 85% of your estimates are either too conservative or spot on. As before, there are eight Little Slips, four Wasted Mornings, two Lost Days, and a Black Cygnet.
With 20% of your tasks coming in early, and 15% coming in late, how long would you expect the average project to take?
| Number of tasks | Type of task | Duration | Total (hours) |
|---|---|---|---|
| 20 | Minor Victory | .9 | 18 |
| 65 | On Time | 1.00 | 65 |
| 8 | Little Slip | 2 | 16 |
| 4 | Wasted Morning | 4 | 16 |
| 2 | Lost Day | 8 | 16 |
| 1 | Black Cygnet | 16 | 16 |
| 100 | 147 |
That’s right: even though your estimation of tasks is more accurate than in the first example above, the average project would come in 47% late. That is, you thought it would take two and a half weeks, and in fact, it’s going to take more than three and a half weeks. Mind you, that’s the average, and again that’s based on probability. Just as above, not every project will encounter bad luck, and some projects will run into more bad luck than others. Again, I ran 5,000 projects of 100 tasks each.
| Average Project | 147.24 hours |
| Minimum Length | 105.2 hours |
| Maximum Length | 232 hours |
| On time or early projects | 0 (0.0%) |
| Late projects | 5000 (100.0%) |
| Late by 50% or more | 2022 (40.4%) |
| Late by 100% or more | 30 (0.6%) |
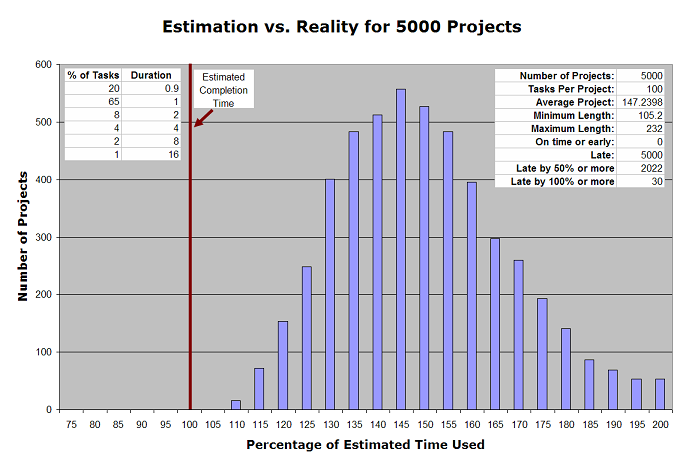
Over 5000 projects, not a single project came in on time. The very best project came in just over 5% late. It had 18 Minor Victories, 77 on-time tasks, four Little Slips, and a Wasted Morning. It successfully avoided the Lost Day and the Black Cygnet. And in being anywhere near on-time, it was exceedingly rare. In fact, only 16 out of 5000 projects were less than 10% late.
Now, these are purely mathematical models. They ignore just about everything we could imagine about self-aware systems, and the ways the systems and their participants influence each other. The only project management activity that we’re really imagining here is the modelling and estimating of tasks into one-hour chunks. Everything that happens after that is down to random luck. Yet I think the Monte Carlo simulations shows that, unmanaged, what we might think of as a small number of surprises and a small amount of disorder can have a big impact.
Note that, in both of the examples above, at least 85% of the tasks come in on time or early overall. At most, only 15% of the tasks are late. It’s the asymmetry of the impact of late tasks that makes the overwhelming majority of projects late. A task that takes one-sixteenth of the time you estimated saves you less that one Regular Task, but a Black Cygnet costs you an extra fifteen Regular Tasks. The combination of the mathematics and the unexpected is relentlessly against you. In order to get around that, you’re going to have to manage something. What are the possible strategies? Let’s talk about that tomorrow.
Hi Michael,
This is one of those things that is perfectly obvious when stated, but needs someone to see it first (like many of the simple tools, gadgets etc that you can’t believe we ever had to do without).
It is logical that the most time you can save on a task is the total time of said task (i.e. if you find that that particular task doesn’t need doing), whereas you have a theoretically infinite amount of time that the task can over-run. The problem is not knowing beforehand which tasks will in fact have these delays. The sooner we develop psychic abilities the better 🙂
Thanks
Andrew
Michael replies: Thank you, Andrew. I just knew you were going to say that, but that’s because I have psychic abilities. 🙂
More seriously, I (and my collegial commenters) will have some suggestions on the subject.
What about ignoring estimates entirely, and whatever time frame is provided for testing is used as-is (ie. we do as much testing as we can during the time alloted)? That way, there are no illusions that we know something for certain, and we can still report on what testing was done.
Michael replies: That’s a possibility. It can be tough or scary to run a business that way, though.
Estimation is certainly a tricky thing to get right, but that doesn’t mean it has to be wrong all the time! Software is tricky to build, but we have found good ways to do it, and continue to innovate and get better.
My team uses several methods to try make estimation as accurate as possible, and minimize bad luck on projects.
I know the definition of a black swan is strongly rooted in it’s unpredictability – but what about the difficulties that happen just below that level? Most of those, I would wager can be minimized with some techniques.
Michael replies: Yes, I agree. Part 3 of this series provides a handful of suggestions out of many possibilities.
I think it is important for a team to accept that they will be held up by situations outside their control during a project, but I am utterly fanatical about ensuring that people learn from black cygnets and try to avoid them in the future.
Let me give you some examples:
– Working through a difficult part of the code and there are hidden complexities that hold up testing or dev? Okay, take your extra hour or day, but take another minute after you complete the task – get a whiteboard and write “Hidden Complexities” at the top and put what you were just working on underneath. Others will follow your lead.
– Machine breaks and needs a day to be fixed? Add a task to get version control on your project, and make sure there is a spare machine around for someone to use in the future.
– By taking this approach you can probably limit your bad luck by a good percentage, and by documenting and disseminating difficulties, estimations get better too. When planning something, bring in your board listing hidden complexities, technical debt, planned holidays for the next few months etc. be prepared to check what estimate you gave something before, and take that into account.
Nice, practical suggestions, which provide excellent examples of what I’m trying to get at in Part 3.
I especially like the egoless aspect of your first sugggestion above.
Of course, bad luck is bad luck and sometimes can’t be avoided – but I think a lot of what we call bad luck can be minimized to some degree.
Yes indeed. The trick, I think, is to be ready to think about the possibility of unthinkable problems, and be prepared to moderate their impact. A great way to do that his to learn about other people’s mistakes via things like the daily newspaper or the Risks Digest—and when you catch yourself saying, “That could never happen here!”, ask “Why not?” and “What would we do if it did?”
Thanks for adding to the conversation.
Interesting experiments. An issue I have with your conclusion is that I don’t think that a 147 hour result necessarily has to be a week late. At a certain point you will work extra hours and though you may be late, it may be only 20% late and not 47% (though you’ve definitely done 47% more work than you intended).
Michael replies: Yes, working overtime is a way around the problem every now and again. But note, I’m not showing that this model that we have to work an occasional day or two extra. Remember, none of the projects were on time. Under this model (and yes, it is only a model), on average you’re working half as much again as you thought you were. That’s a constant (on average) 60 hours a week. The darkest thought in all this: I bet the 60-hour week thing is familiar to lots of people.
Generally in a development project, the testing is what suffers from poor estimation. If developers are late in their milestones, the final product deadline doesn’t move and there is simply less time to test. So, the question is: how do we deal with not enough time to test? My take on the Pareto Principle is that 20% of the testing time can accomplish 80% of the coverage. While obviously not exact proportions, the concept is true and the risk generally isn’t so bad as thinking that if testing time is cut to x% that we can only test x% of the product.
I’ll have a different thing to say about testing in a future post. But for now, let me say that there’s no reason for testers to feel that they don’t have enough time to test. The amount of time for testing is ultimately decided by our client.
Here are two good quotes on estimation from http://www.abeheward.com/?p=164 (Abe Heward):
“Halve your expected revenues; double your expected costs.”
“The rule of thumb I once heard for improving a development time estimate is double the number and increase the units. When I hear 2 weeks, I think four months.”
I like Abe’s stuff; he’s a fellow atracygnologist.
I am still trying to get estimating and project scheduling right.
Michael replies: Good luck with that. 🙂 Predicition is very difficult, especially when it’s about the future (that’s sometimes attributed to Yogi Berra).
I thought the priority of features was supposed to help this problem. “We can finish on time because we always have something we can deliver. We just might miss the lowest priority features.”
Priority of features didn’t always help in features with many parts, a chain of stories that seem to be prerequisites. I hear that should be solved (prerequisites) with stubs and drivers. I rarely see that approach taken because 1) people aren’t good at making stubs and drivers, and 2) people don’t want to invest in becoming good because it takes too much time.
Side Note: There is a road construction project going on by my house. They are building a new bridge. The construction crew cleared land and build a small bridge. After the clearing and small bridge making, the construction crew had room to work to make the big bridge. I see an investment lesson in there for software projects.
Regarding the bad black swans, they fall into three categories: caused by me, caused by somebody else, and caused by some uncontrollable chain of events. Problems caused by me are tough because I don’t foresee my mistakes or I wouldn’t make them. Problems caused by somebody else are difficult because you may know they are coming but you have to influence them properly to prevent them. The third are impossible to stop.
Identifying project risks is an attempt to prevent or mitigate the Black Swans. It’s tough to do, and really tough without a good practice. I see people do a Mickey Mouse job of predicting risks most of the time. I see people do a poor job of categorizing the risks. They don’t learn from onforeseen risks. The worst violation is overcompensating for risks that will probably not happen again.
I’ll keep reading and trying to learn…
Thanks for a very thoughtful post. It’s prompted some ideas that I’ll explore in future items in this series.
See also Joel Spolsky’s post on monte carlo estimation at http://www.joelonsoftware.com/items/2007/10/26.html
Michael replies: Yes, a nice link to the discussion. Thanks, Kerry.
[…] I was chatting with. I felt terribly guilty at this point, having not read his recent posts on Estimations & Black Swans. He was very excited about them & going by the buzz on twitter around this I’ll really have […]
Hi Michael.
Just seen this. It’s worth looking at tools from people like Risk Decisions (e.g. http://www.riskdecisions.com/274.html) if you want to do experiments like this — they’ve been doing Monte Carlo simulation of the impact of estimating errors & suchlike on project plans for a decade or so, that I’m aware of. So it’s not that the project management community, overall, isn’t aware of this — just that most project managers aren’t really looking for nuanced answers to their questions.
The risk I see with Monte Carlo simulation is that it can create a sense of false safety. People tend to think that, having done a huge number of mathematical simulations, then their outputs must now be a lot more accurate. But the quality of the outputs is heavily dependent on assumptions (such as the distribution of of errors) and still, by definition, can’t account for true black swans.
Michael replies: The point of the Monte Carlo simulation that I’ve presented here (and of Monte Carlo simulations generally) is that the outputs—predictions about the future—cannot be presumed to be “accurate”. I had hoped that The Black Swan (the book) would have helped people to wake up to this, but… well, you know. I just caught myself having similar hopes about Daniel Kahneman’s new book, Thinking Fast and Slow, but then I caught myself. You know.
The real answer isn’t to try to create ever more accurate estimates and plans — it’s to run projects in ways that are more resilient to unanticipated events. (Although simulations like this can be a great way to help build awareness of just how wide the uncertainty really is.)
Cheers
Graham
Michael replies: That’s exactly the point of the blog posts that follow this one. Read on!
Hi Michael,
I know I’m probably too late for the conversation but this is the first time I see your post.
We did publish a very comprehensive articles on Black swan risks in program management (which are more or less the same as those in project management), and I invite you to read this post whenever you get the chance. It is written by a Program Manager in a very large construction firm.
[…] estimate’. (See the idea of black swans and the known unknown vs the unknown unknown, or this set of blog posts by Michael Bolton.) Now why would our model be wrong? Assuming we’re not clinging on to some […]
[…] “utopic estimations” here. Michael Bolton wrote a lot about estimation here, here and here. He explains that testing is an open-ended task which depends on the quality of the products under […]
[…] “Project Estimation and Black Swans” (Blog Series) by Michael Bolton […]
Hi, I started to read the book Black Swan by Mr. Taleb and recall him talking about predicting the future with regards to construction time estimating. I was trying to find direct quotes from the book about it but found many references and resources like this. As it so happens my husband and I own a millwork company and we are subs on large major renovations in which there are lots of other players. In our experience, most projects–due to many factors–come in over the predicted date. Also, in our experience, wealthy people don’t acknowledge black swans and many pull a “Trump” whenever they can (paying 60¢ on the dollar because they know most of us don’t have the legal firepower). If we were to try and be more realistic with our bids’ time estimates we would probably lose contracts to the company that promises the moon (and then the job inevitably goes over). The only time jobs go within time frame is when we have “summer hours” projects but everyone involved can command a premium and pay everyone OT to get it done. We are currently being “Trumped” by a contractor right now because the client is upset the job went over but there is nothing in contract about time limit or the building charging them past a certain date. It’s infuriating and nerve wracking when we are having a tough time making payroll and paying bills. Both contractor and client are multi millionaires and I’m trying to figure out how we’re going to make payroll without going beyond our business line of credit. It sucks.
Michael replies: It does suck.
“If we were to try and be more realistic with our bids’ time estimates we would probably lose contracts to the company that promises the moon (and then the job inevitably goes over).” That, alas, is a decision that every business person has to make eventually, if not constantly. It’s central to what customer relationship management is really all about.
If you’re very savvy about estimates (which I presume are somewhat easier in the construction business than in software, but maybe not by much), that can be a competitive advantage over the long run. You’ll get beaten for contracts by the fly-by-night people. When that happens, make sure you stay on good terms with the customer—and let them know you’re available to help them out when the other vendor gets in trouble. Which they will.
[…] Bolton supplies a perfect instance of challenge estimation fallacies with Black Swan-like occasions. In his instance, a challenge is estimated to take 100 hours with […]
[…] Project estimation and black swans […]
[…] Bolton provides a great example of project estimation fallacies with Black Swan-like events. In his example, a project is estimated to take 100 hours with each […]