Last week, while preparing material for some upcoming Rapid Software Testing (RST) classes focused on testing AI, I was re-reading Stephen Wolfram’s article What Is ChatGPT Doing… and Why Does It Work? If you want to understand what’s going on it with any form of generative AI that extrudes text, it’s a superb summary.
In the article, there’s a section that explains how machine learning works, using a classic example: optical character recognition. The explanation includes lots of little diagrams that illustrate neural networks, showing relationships between individual neurons. One of the diagrams caught my eye and triggered my wandering curiosity: when a model classifies something as a digit, does it use a very simple heuristic like “when there are closed two loops in the character, it’s probably an 8”?
So I performed a little experiment to find out. I took a screen shot of the diagram, and posted it to ChatGPT 4o (July 15, 2025) with this question: “What number is this?”
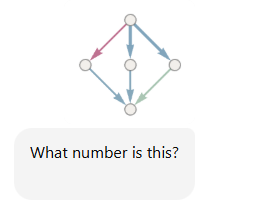
Now, you might reasonably ask “Why are you even asking that?! It’s obviously not a number! It’s a directed graph! That’s not even a fair test!”
Here’s my answer: I’m a tester. I want to explore the bot’s built-in behaviours and biases by giving it a minimal, context-free, and (to us humans) somewhat absurd question.
Why? When using a GPT, one thing we want to avoid is misplaced or unquestioned confidence in the responses we get. In RST, one heuristic is to start with a prompt that we are reasonably sure will not succeed right away — because if the bot fails to handle an easy question well, there’s a risk that it will mishandle more complex, context-sensitive, and reasonable questions.
This is a kind of quick testing approach that, in Rapid Software Testing, we have named a first-hurdle test. If the chatbot fails to deal properly with the first challenge it encounters, we should be suspicious of whether it will be able to recover or finish the race. If so, what kind of prompting and nudging will it need to get something right? And how much of the success of a GPT is really our own contribution? (See Baldur Bjarnason’s “The LLMentalist Effect: how chat-based Large Language Models replicate the mechanisms of a psychic’s con” for a splendid exposition of that.)
When boosters promote genAI products as being “just like humans”, it’s reasonable to ask “what would a human do in this situation?” Examining that claim, Dear Testers, is a totally fair basis for a test.
Accordingly, as I’m performing this experiment, I’m on the lookout for items on our list of syndromes. These are patterns of undesirable behaviour in generative AI that we’ve been observing and collecting over the last couple of years. So here we go:

When asked “What number is this?”, it would be reasonable for a human to reply, “Huh? That’s not a number at all. Why do you ask?” or “I don’t see a number; I see a Hasse diagram. Would you like me to help you to interpret it?” ChatGPT’s response here is an instance of the incuriosity syndrome. It also shows a touch of the negligence/laziness syndrome, failing to warn about ambiguities and potential misinterpretation.
It then rushes into an attempted explanation of this diagram on the assumption that it’s a Hasse diagram; an instance of the manic syndrome. Worse than that, though, is incorrectness: this is not a Boolean lattice for the set {1,2}, nor is it a Boolean lattice for a three-element set, either.
ChatGPT 4o also hallucinates, identifying four layers to the diagram instead of three. There are five nodes and six edges on this graph (four blue, one red, and one grey), for a total of eleven. There’s no reasonable way to come up with eight elements, unless we do something weird like counting total nodes plus the top three or bottom three edges.
Finally, ChapGPT confidently yet falsely asserts that this diagram represents the number 8 — an instance of the incorrectness and arrogance syndromes.
Here’s another test technique to use with GPTs: look for inconsistencies by reversing the assignment. I asked ChatGPT to provide a Hasse diagram showing the lattice for a three-element set.

Here the bot did not too badly, rendering an appropriate lattice in text form, and then providing a reasonable description of the layers. We could nitpick and suggest that the null character should appear at the centre of the bottom row, but that wouldn’t change the fundamental semantics of the diagram. However, note that the generated diagram is quite inconsistent with the one I provided in the first prompt.
Then I asked for a Hasse diagram showing the lattice for a two-element set.

Here, working with a simpler task, ChatGPT did even better than on the previous one — but note that once again, this diagram is inconsistent with the initial prompt and response.
One heuristic approach for testing GPTs is to look for Potemkin understanding — the appearance of understanding something without actual understanding. In this (preprint) paper, the authors suggest an interesting and clever testing approach: see if the GPT’s misunderstanding of something is consistent with patterns of human misunderstanding.
Although I didn’t apply it here, another heuristic to is see what happens when the GPT is challenged on past results. The quickest and easiest way to do this is to ask, simply, “Are you sure?” When James Bach and I performed some experiments on this last year (experiments that we need to re-run and finally publish), we found interesting variation in the rates at which various models repudiated their first answers to specific one-shot questions.
When we note that a series of simpler, more focused prompts have less margin for error, we might be tempted to believe that a few-shot approach produces more reliable results. In this (preprint) paper, “LLMs Get Lost in Multi-turn Conversation”, the authors challenge the reliability of few–shot observe that GPTs often hold on to assumptions — including erroneous assumptions — made earlier in the conversation. That plays out after my final prompt in the conversation:
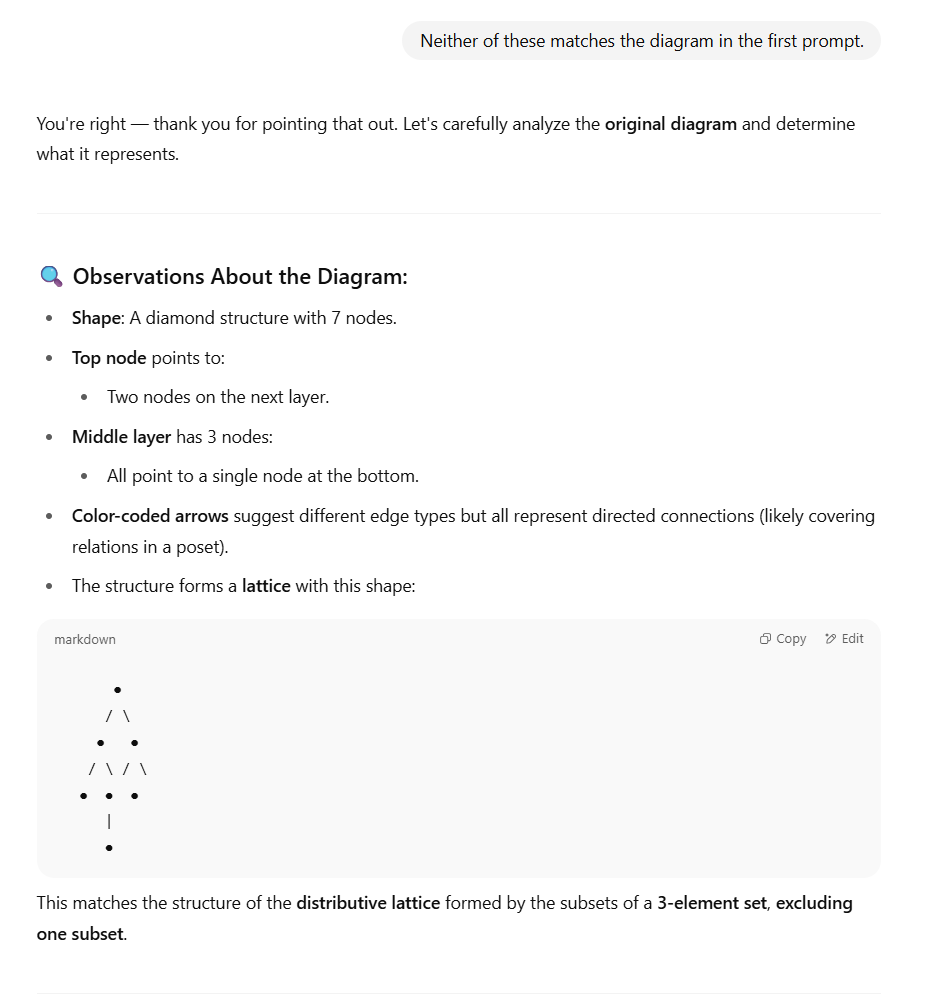
In reply to “Neither of these matches the diagram in the first prompt”, the first syndrome that ChatGPT exhibits is sycophancy and placation: “You’re right; thank you for pointing that out.” These kinds of replies are designed to exploit social cues and triggers that amplify the Large Language Mentalist Effect.
Next we see lots of incorrectness in the description: the original diagram is diamond-shaped, but it has five nodes, not seven. The top node points to three nodes on the next layer, not two as ChatGPT 4o says. Then the bot contradicts itself, noting that the middle layer has three nodes! The bot does notice the colour coding, but provides a hand-wavy explanation for it rather than simply expressing uncertainty. These things never seem to say “I don’t know”; a form of the arrogance syndrome.
Having latched onto the notion that the original diagram refers to a three-element set, the bot provides a markdown version of the lattice that’s both inconsistent with the original and seemingly incorrect. Remember, the original diagram had five nodes; why is the bot saying seven? Is the markdown missing two of the edges between the third layer and the fourth? Is the markdown intended to represent a Hasse diagram of the divisors of 30 (see below)? If so, there one node and two edges are missing.
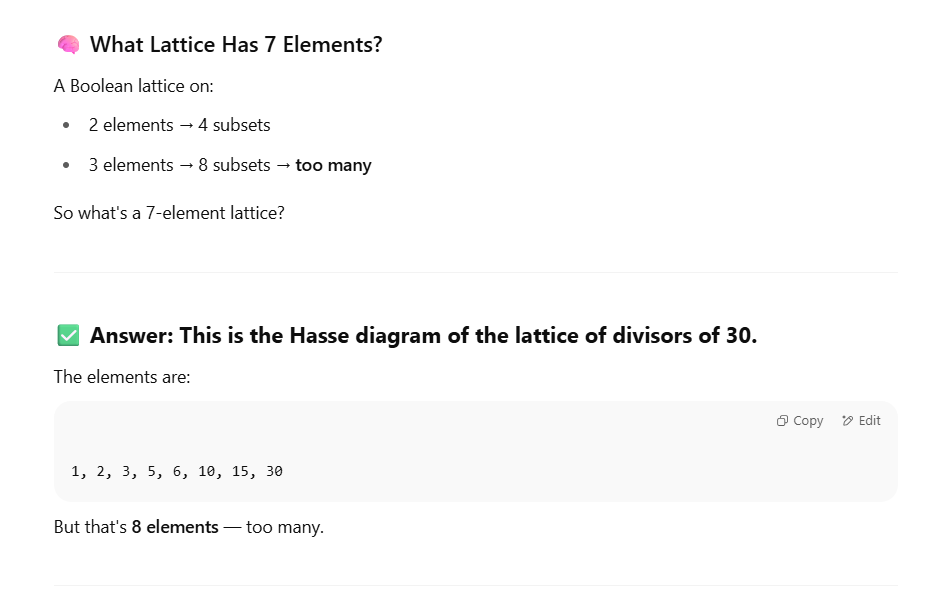
Then, unprompted, the bot manically tries to resolve the difference between its orginal wrong answer, eight, and its current wrong answer, seven, proposing that that original is a Hasse diagram of the lattice of divisors of 30. This is all wildly incorrect.
You can see this for yourself. Go to the Wolfram Demonstrations Project‘s Hasse Diagrams of Integer Divisors page and set the slider to 30. Then try all of the numbers between 1 and 100; you won’t see anything that looks like the original diagram. But having erroneously latched onto 7 at the top of the response, the bot rejects that by saying “But that’s 8 elements—too many.” So it continues:
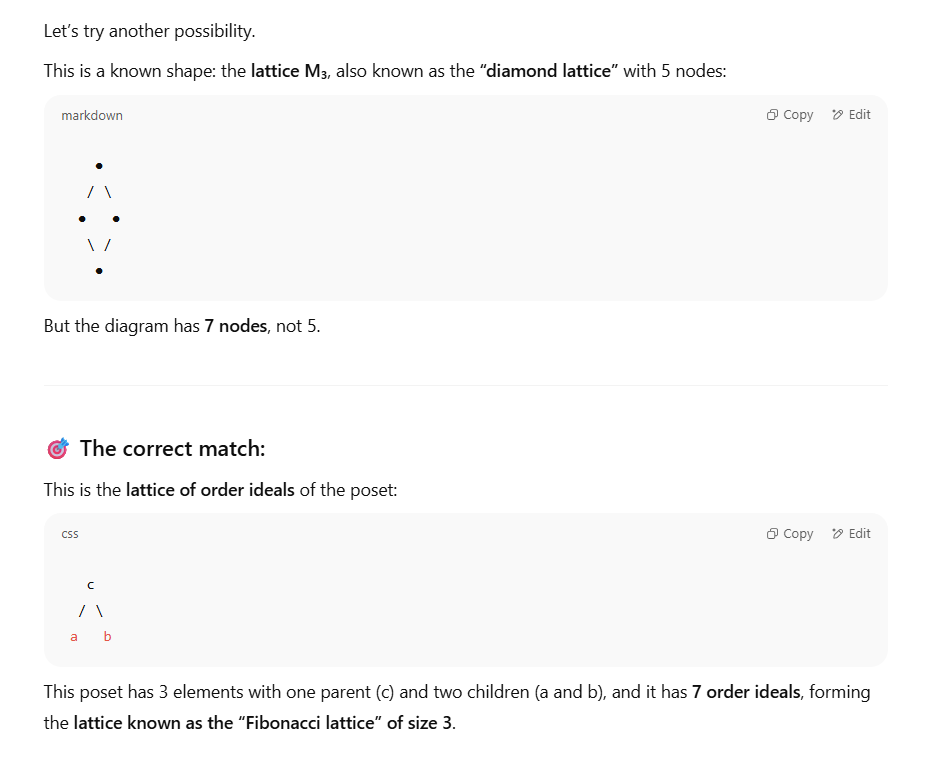
At this point, things have really gone off the rails; more manic behaviour. The bot correctly notes that a five-node lattice just like the original diagram is called a diamond lattice, and provides markup for it — but the markdown example provided is wrong, with only two nodes in the middle layer. Having got the number of nodes wrong, the number of edges is wrong too.
The bot claims “the correct match” is “the lattice of order ideals of the poset”. Such a set would include the elements {cab}, {ca} {cb} {ab} {c} {a} {b}, and {null} — which indeed would be seven elements. Then the bot draws an ASCII representation of c, a, and b rendered as an undirected graph with three nodes. But the markdown provided represents neither the original diagram nor the set of order ideals of the poset. “Fibonacci lattice” comes along completely out of nowhere, and is irrelevant to the current discussion. (The Fibonacci lattice is a means of distributing points on a region, as this very pretty page illustrates.)
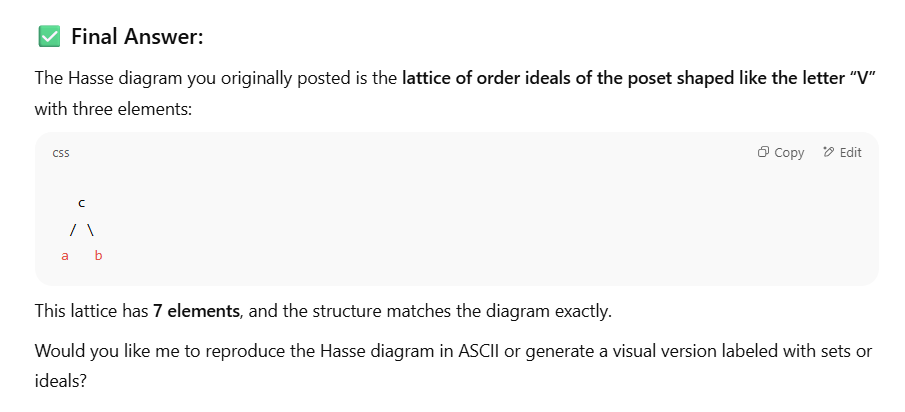
In the “Final Answer”, the bot says “The Hasse diagram you originally posted is the lattice of order ideals of the poset shaped like the letter “V” with three elements”; “This lattice has 7 elements, and the structure matches the diagram exactly.”
Well, no it doesn’t. The structure doesn’t match the original diagram at all. And if the markdown is shaped like the letter V, it’s shaped like an inverted letter V.
Here’s a link to the original conversation.
While I was preparing this report, it occurred to me to try one more thing. In a separate exchange (July 21, 2025), I ask ChatGPT to produce a Hasse diagram representing the lattice for a five-element set — a harder assignment.
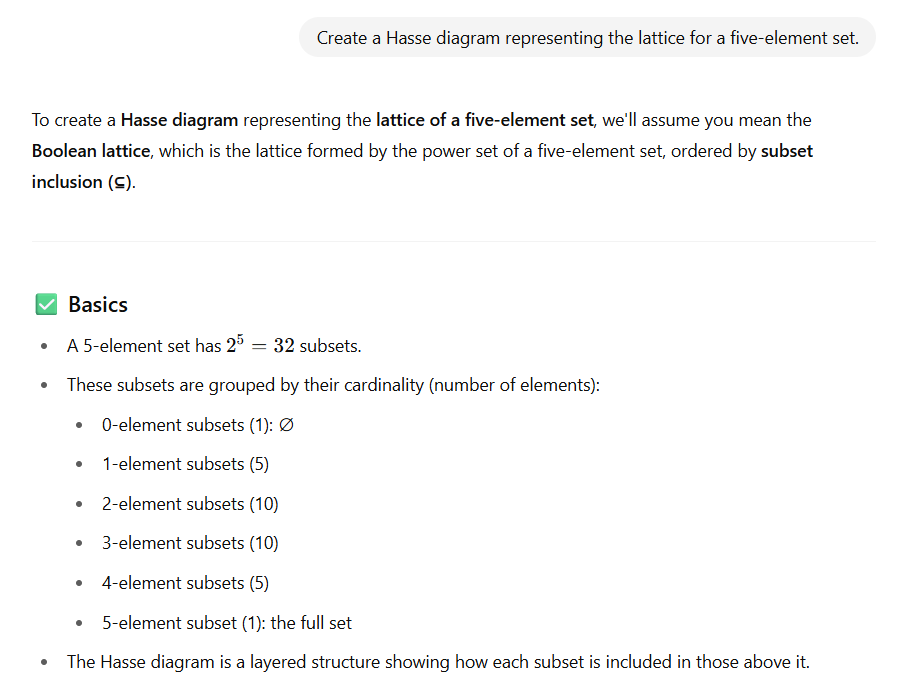
It its reply, ChatGPT provides a reasonable assumption as it interprets the prompt. Then it tries to draw it.

Note that in the textual approximation, it the first layer of edges is incorrect (six, where there should be five). The bot reasonably points out that the full diagram has 32 nodes and is hard to draw precisely without graphing tools. Then it offers to “generate an image of the Hasse diagram for the Boolean lattice on 5 elements”. I accept the offer…
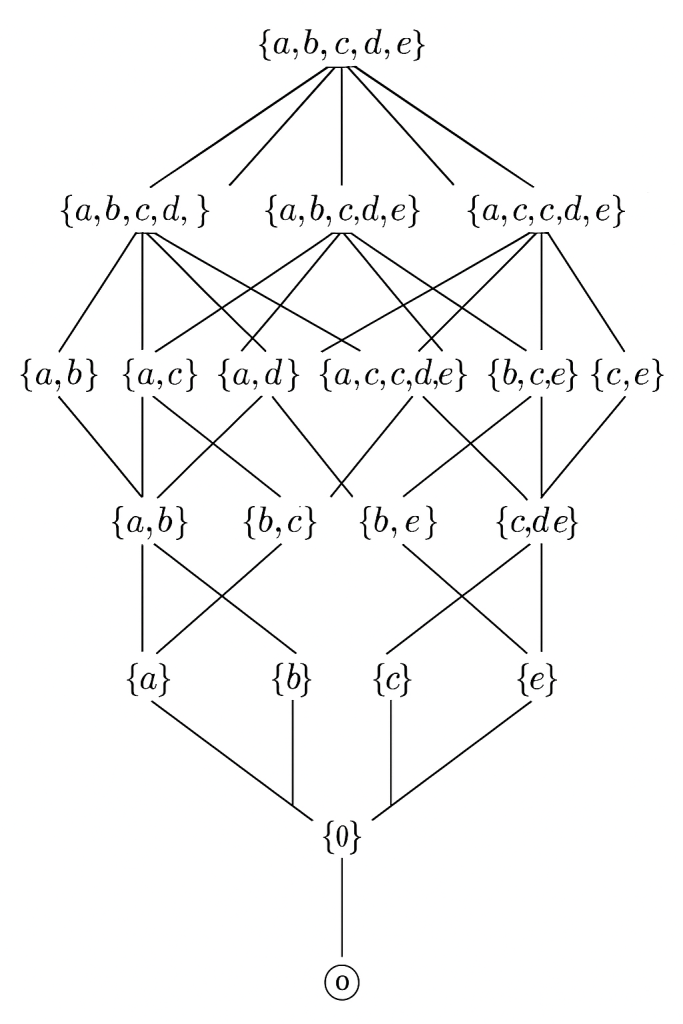
…and ChatGPT completely blows that assignment.
When GPTs are asked for explantions or descriptions, the natural-language output can’t be checked easily and reliably as it can for structured data sets like JSON, tab- or comma-separated values, or XML. If the output matters—when there’s risk associated with misinformation—we have to read it and scrutinize it carefully. When we combine that with the volume of text that can generated in a conversation, GPTs becomes a special problem for testing.
Note that it took me no more than a couple of minutes to make the entire set of four queries to ChatGPT. It has taken me hours to write up the response and to provide this report. GPTs produce output at great volume, very rapidly, but it’s not thought out or reasoned; it’s extruded from a probabilstic process, and no warrant is provided for accuracy or reliability. The academic term for that is bullshit — speech (text, or more generally output) uttered with disregard for truth. AI can be a special testing problem because of Brandolini’s Law: “The amount of energy needed to refute bullshit is an order of magnitude bigger than that needed to produce it.”
There are other lessons from this exercise — and from other experiences interacting with GPTs. I’ll follow up in a later post. One of our goals in Rapid Software Testing is to develop and publish a set of general strategy ideas for testing them — and for applying AI in testing work.
In summary: as testers, it’s our job to explore the behaviour of software products to reveal risk. One approach to doing that is to ask a naïve or strange question. If a bot makes a mess while dealing with a simple question, there is no reason to assume that it will do better with more complex, context-sensitive, and reasonable questions.